
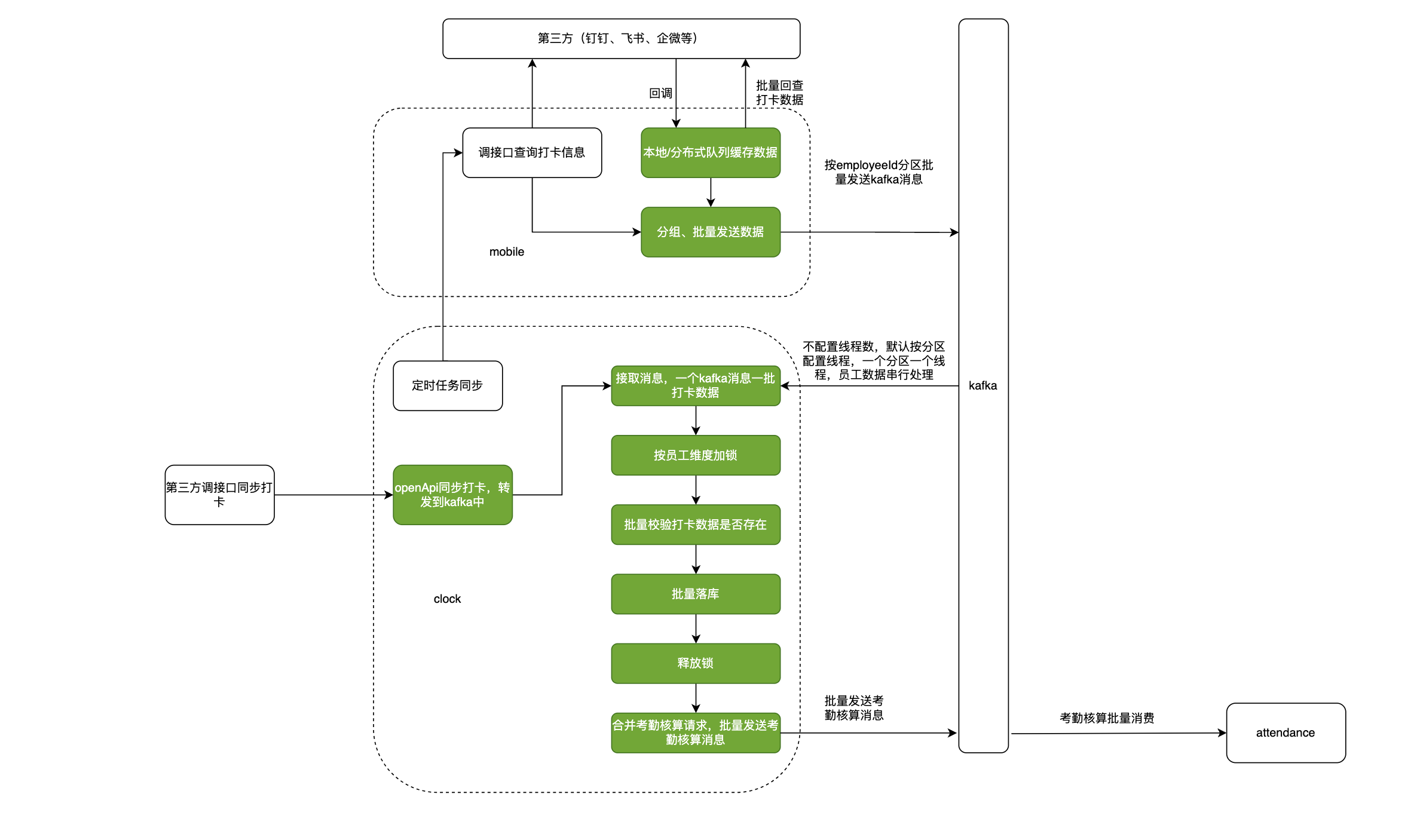
打卡业务串讲
打卡业务总览关键词
打卡业务中经常涉及到的关键词如下:
关键词
说明
示例
打卡规则
打卡规则主要是约束用户可打卡的方式:外勤打卡、内勤打卡;租户办公位置的gps或wifi信息(用来判断是否是有效打卡);打卡动作的约束限制:是否需要附件、是否需要拍照等,目前打卡规则的配置是依附于考勤组规则配置页面
打卡渠道
打卡渠道是用来标识用户使用的是哪种渠道进行的打卡动作数据来源的主要渠道:拉取第三方: 企微、钉钉(钉钉打卡、钉钉签到)、飞书Moka打卡:moka移动端打卡考勤机打卡: 中控、天敏考勤机第三方主动上报: 使用openApi主动上报
打卡成功提示
打卡成功后,给用户发送打卡动作操作成功的提醒通知
员工打卡提醒
在上班时间范围和下班时间范围内主动发送通知,提醒用户进行打卡操作配置项:考勤组中设置上、下班的提醒时间(在班次前后多久)
例如设置的班次时间为9点~18点 :则上班打卡提醒:打卡前10分钟, 下班打卡提醒:下班后5分钟上班提醒通知发送时间:8点50分下班提醒通知发送时间:18点05分
打卡方式
内勤打卡:在租户办公点有效范围内的打卡行为属于内 ...
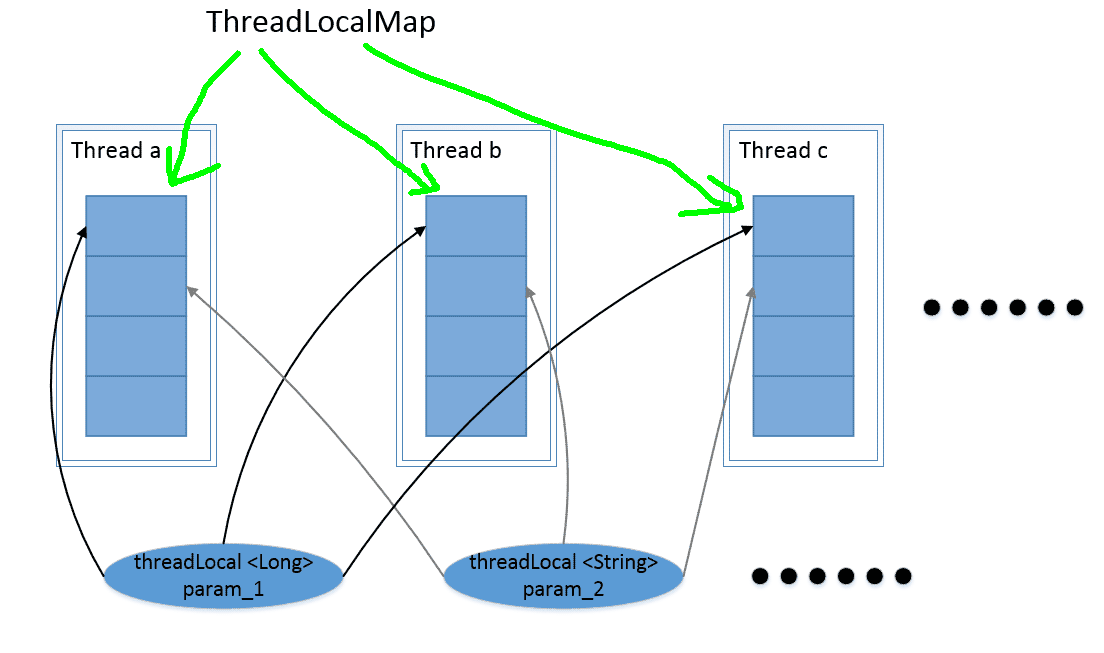
浅谈ThreadLocal中的内存泄漏问题
之前在看java guide上ThreadLocal的相关内容时,看的云里雾里,当时只知道和ThreadLocal底层使用的ThreadLocalMap中Entry的弱引用有关,甚至天真的以为ThreadLocal内存泄漏的原因是弱引用(面试被问到也这么答了/(ㄒoㄒ)/~~😓),今天认真看了一下ThreadLocalMap的源码,才发现并不是这样,而且网上很多错误回答也的确误导了当时的我,究其原因还是自己对于知识的掌握太过心切,欲速则不达,下面就来好好复盘一下这个问题
ThreadLocal用法首先要知道Thread 类中有一个 threadLocals 和 一个 inheritableThreadLocals 变量,它们都是 ThreadLocalMap 类型的变量,可以把 ThreadLocalMap 理解为ThreadLocal 类实现的定制化的 HashMap:
123//Thread类中有两个ThreadLocalMap类型的变量ThreadLocal.ThreadLocalMap threadLocals = null;ThreadLocal.T ...
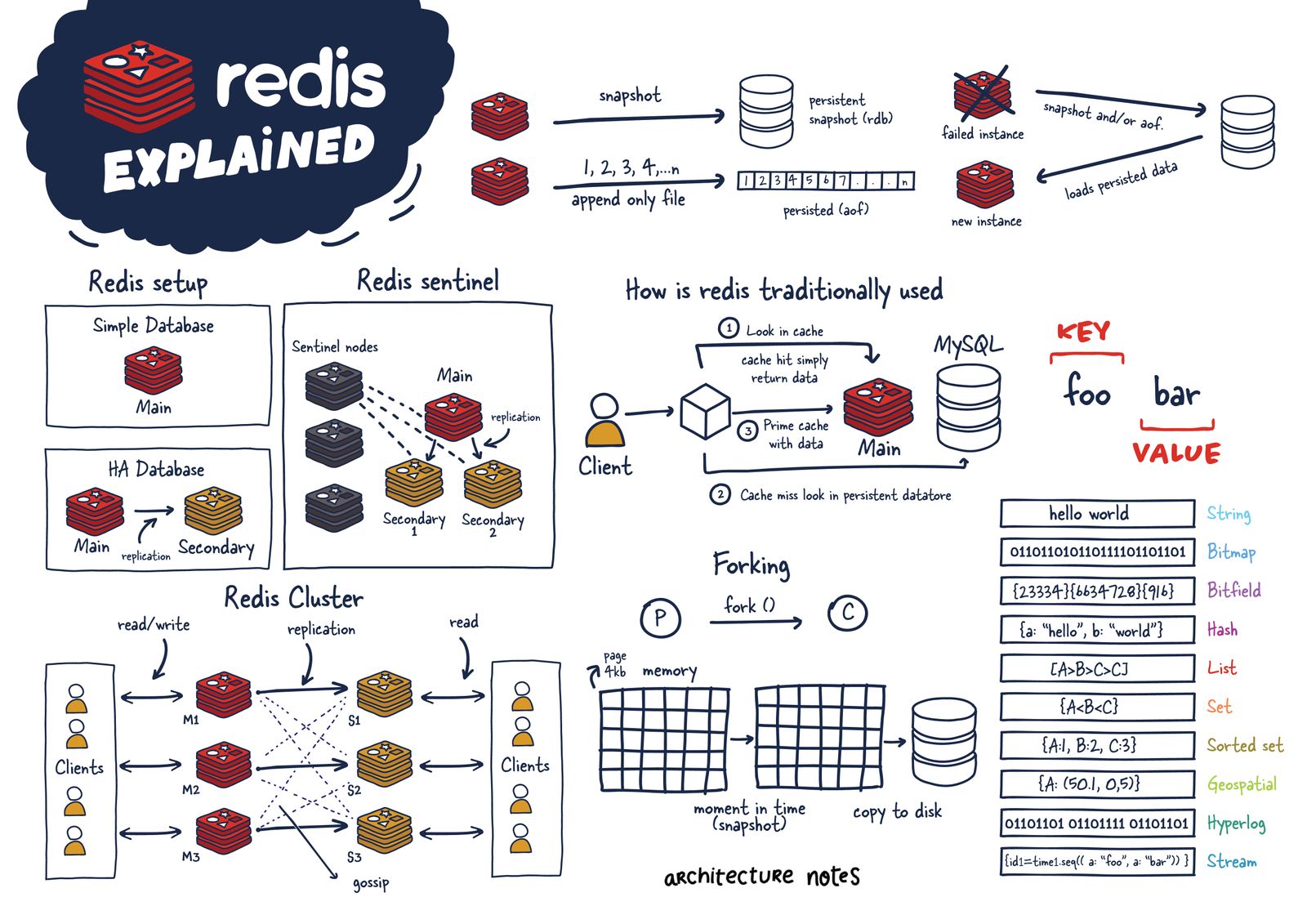
Redis-Review
基本数据类型StringString 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)
SDS 不仅可以保存文本数据,还可以保存二进制数据。SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据
SDS 获取字符串长度的时间复杂度是 O(1) 因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用 len 属性记录了字符串长度,所以复杂度为 O(1)
应用场景
(1)String常用来缓存对象,有以下两种方式:
直接缓存整个对象的JSON, SET user:1 '{"name":"xiaolin", "age":18}'
采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子: MSET user:1:name xiaolin user:1:age ...

Rocketmq
MessageQueue使用消息队列的优势在于:
应用解耦:消费者存活与否不影响生产者,且如果增加消费者,无需修改消费者端的代码(只需让mq多复制一份消息给新消费者)
异步提速:生产者一旦发送完消息就可以继续进行下一步业务逻辑
削峰填谷: 使用mq来限制消费者消费速度,这样依赖高峰期产生的数据会被积压在mq中,不会对消费者造成巨大压力,而在高峰期过后的一段时间,消费者消费消息的速度依然维持在一个适中的速度(相比平常),这就叫填谷
使用mq自然也带来了劣势:
系统可用性降低:一旦mq宕机则整个系统都会故障
系统复杂度提高
带来一致性问题:假如A系统处理完业务后,,通过mq给B、C、D三个系统发送消息数据,如果B系统处理成功,而C、D系统处理失败,这样就会带来数据一致性问题
消息顺序性
消息丢失
消息一致性
消息重复使用
Rocketmq原理
安装与测试1234win10下安装所需环境为:jdk 1.8(版本过高可能会无法启动nameserv)mavenrocketmq 4.4
1、启动NAMESERVER
cmd命令框执行进入至‘MQ文件夹\bin’下(端口9876)
...
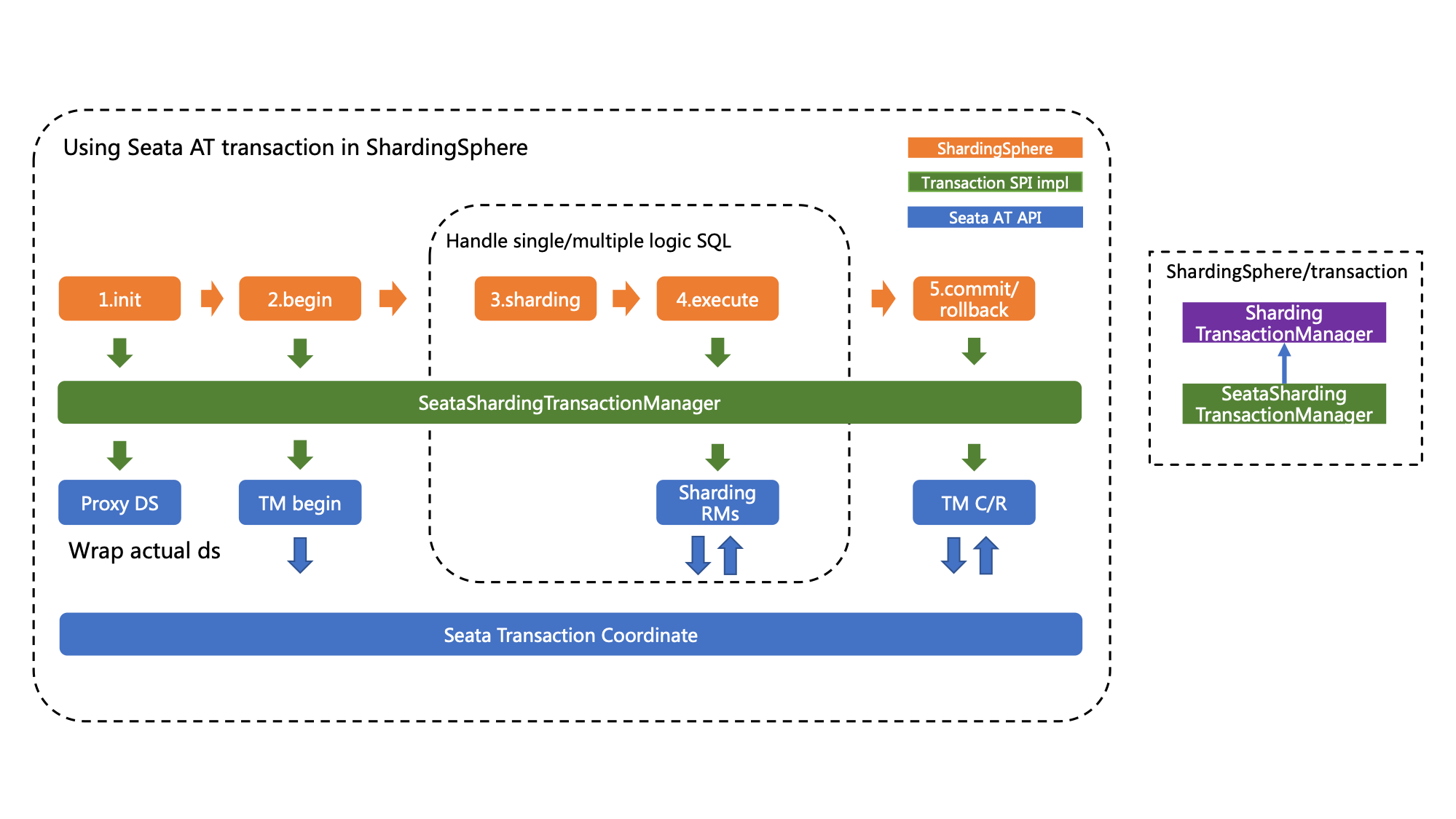
SpringCloud-Seata
SpringCloud Gateway网关简介在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢? 如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去用。
这样的架构,会存在着诸多的问题:
每个业务都会需要鉴权、限流、权限校验、跨域等逻辑,如果每个业务都各自为战,自己造轮子实现一遍,会 很蛋疼,完全可以抽出来,放到一个统一的地方去做
如果业务量比较简单的话,这种方式前期不会有什么问题,但随着业务越来越复杂,比如淘宝、亚马逊打开一 个页面可能会涉及到数百个微服务协同工作,如果每一个微服务都分配一个域名的话,一方面客户端代码会很难维护,涉及到数百个域名,另一方面是连接数的瓶颈,想象一下你打开一个APP,通过抓包发现涉及到了数百个远程 调用,这在移动端下会显得非常低效
后期如果需要对微服务进行重构的话,也会变的非常麻烦,需要客户端配合你一起进行改造,比如商品服务, 随着业务变的越来越复杂,后期需要进行拆分成多个微服务,这个时候对外提供的服务也需要拆分成多个,同时需要客户端配合进行改造
Spring Cloud Gateway 是 ...

SpringCloud-Feign
Ribbon负载均衡(1)负载均衡是我们处理高并发、缓解网络压力和进行服务端扩容的重要手段之一,但是一般情况下我们所说的负载均衡通常都是指服务端负载均衡,服务端负载均衡又分为两种,一种是硬件负载均衡,还有一种是软件负载均衡。硬件负载均衡主要通过在服务器节点之间安装专门用于负载均衡的设备,常见的如F5。软件负载均衡则主要是在服务器上安装一些具有负载均衡功能的软件来完成请求分发进而实现负载均衡,常见的就是Nginx
(2)另一种则是客户端自己做负载均衡,根据自己的请求情况做负载,Ribbon就属于客户端自己来做负载均衡
(3)无论是硬件负载均衡还是软件负载均衡都会维护一个可用的服务端清单,然后通过心跳机制来删除故障的服务端节点以保证清单中都是可以正常访问的服务端节点,此时当客户端的请求到达负载均衡服务器时,负载均衡服务器按照某种配置好的规则从可用服务端清单中选出一台服务器去处理客户端的请求。这就是服务端负载均衡。
客户端负载均衡
“Ribbo是一个基于HTTP和TCP的客户端负载均衡器,当我们将Ribbon和Eureka一起使用时,Ribbon会从Eureka注册中心去获取服务端列表,然后 ...
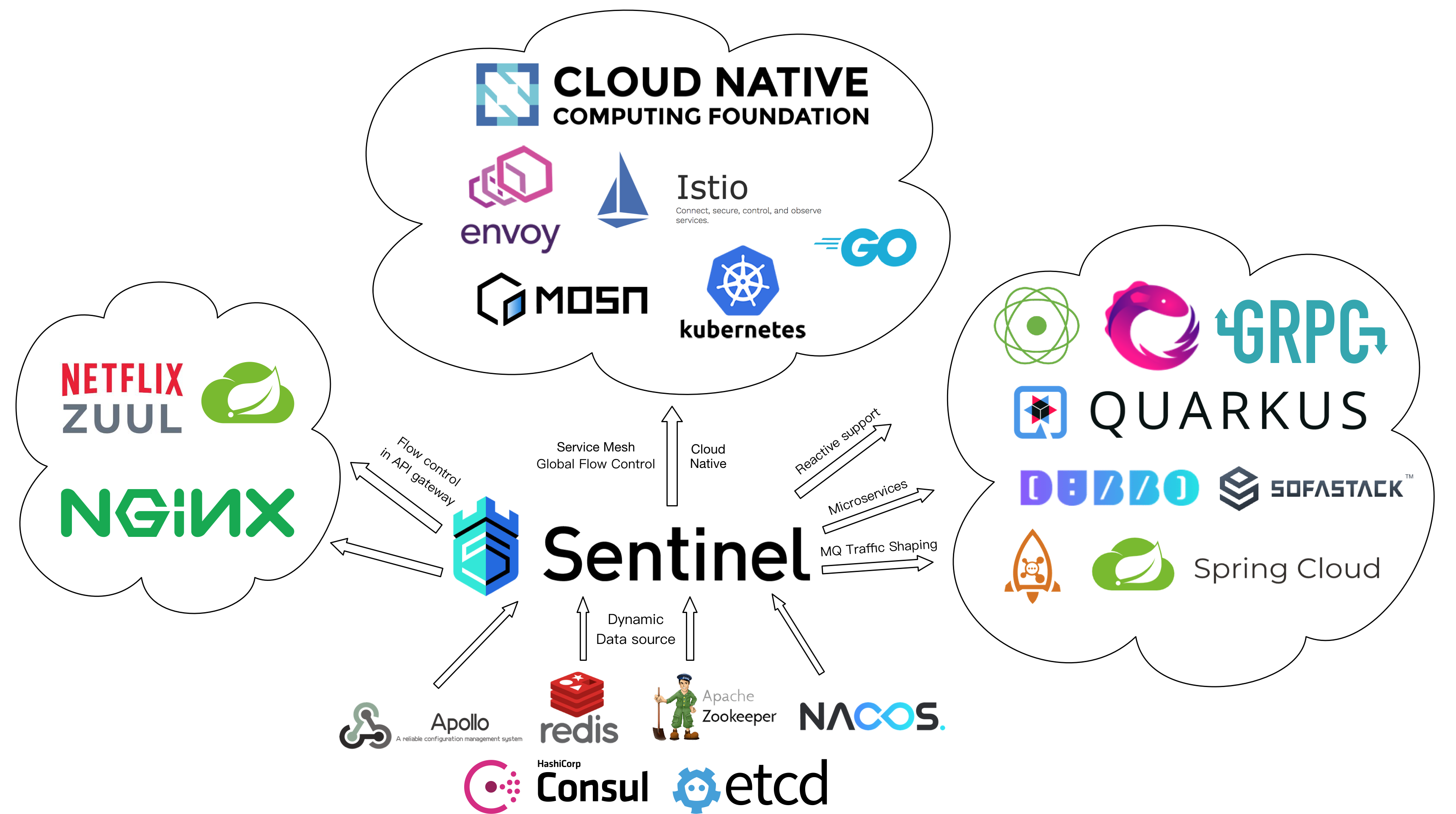
SpringCloud(1)-Nacos
首先需要启动一个微服务项目,这里以idea2022.1版本为例:
新建父工程(经Spring Initializr创建)
在父工程下添加多个Module(选择maven Archetype)
然后为每个服务配置SpringbootApplication
1234567891011package com.lzc;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublic class UserApplication{ public static void main( String[] args ) { SpringApplication.run(UserApplication.class,args); }}
启动多个服务后,可以看到idea下方的Services会显示已启动过的服 ...

视频语义分割(1)
视频分割主要分为以下三种:
Video Object Segmentation(视频对象分割):从视频所有图像帧中把感兴趣的物体区域的分割出来, 主要数据集有 DAVIS、Youtube-VOS(Video Object Segmentation)、Youtube-VIS(Video Instance Segmentation)
Video Semantic Segmentation(视频语义分割):相对于视频物体分割,VSS需要对每个像素点均给出一个类别预测,主要数据集有 Cityscapes、NYUv2、CamVid、VSPW(CVPR2021)
Video Panoptic Segmentation(视频全景分割):需要把同一类的不同物体均区分出来,而语义分割只需要区分出不同类别,数据集有Cityscapes
视频语义分割 目前视频语义分割主要研究的重点大致有两个方向:第一个是如何利用视频帧之间的时序信息来提高图像分割的精度,第二个是如何利用帧之间的相似性来减少模型计算量,提高模型的运行速度和吞吐量。视频分割任务的评估指标和图像语义分割相同均为mIOU(mean Inters ...

Mysql-锁机制
悲观(乐观)锁乐观锁和悲观锁并不是锁,而是锁的设计思想
乐观锁:乐观锁(Optimistic Locking)认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,也就是不采用数据库自身的锁机制,而是通过程序来实现。在程序上,我们可以采用版本号机制或者时间戳机制实现。
乐观锁的版本号机制在表中设计一个版本字段 version,第一次读的时候,会获取 version 字段的取值。然后对数据进行更新或删除操作时,会执行UPDATE … SET version=version+1 WHERE version=version。此时如果已经有事务对这条数据进行了更改,修改就不会成功。
乐观锁的时间戳机制时间戳和版本号机制一样,也是在更新提交的时候,将当前数据的时间戳和更新之前取得的时间戳进行比较,如果两者一致则更新成功,否则就是版本冲突。
悲观锁:悲观锁(Pessimistic Locking)也是一种思想,对数据被其他事务的修改持保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排它性。
总结:乐观锁适合读操作多的场景,相对来说写的操作比较 ...

SpringSecurity
认证-鉴权一般的web项目当中,总会有登陆和鉴权的需求
认证:验证当前访问的用户是不是本系统中的用户。确定是哪一个具体的用户。
鉴权:经过认证,判断当前登陆用户有没有权限来执行某个操作。
所以说,安全框架SpringSecurity当中,必定会有认证和鉴权的两大核心功能。
入门demo(1)项目中引入SpringSecurity
12345<!--引入security依赖--><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId></dependency>
(2)引入相关依赖后再次登录localhost:8080 会发现需要先进行登录才能访问(springsecurity内置的):
可以使用console输出的md5值进行登录:Using generated security password: dab4b80e-9 ...