2022年的最后一篇文章😁😋😎
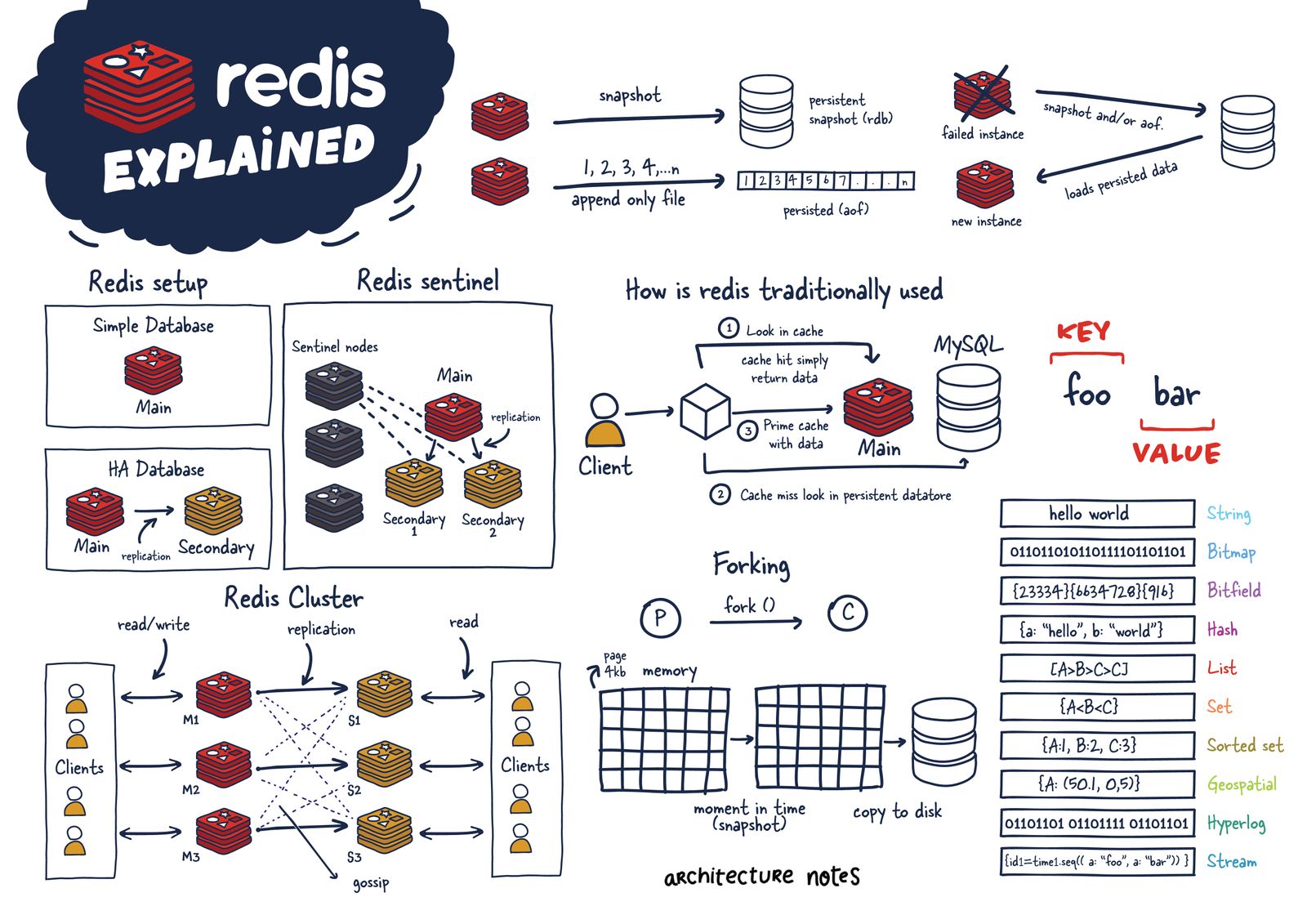
Redis持久化
Redis虽然是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失,为了解决这个问题Redis提供了两种持久化的方案,将内存中的数据保存到磁盘中,避免数据的丢失。
快照持久化(RDB)
BGSAVE
客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork创建一个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求(在刚开始时,父进程与子进程共享内存,直到父进程或子进程对内存进行写操作后,结束共享服务)
SAVE
客户端还可以使用SAVE命令来创建一个快照,接收到SAVE命令的redis服务器在快照创建完毕之前将不再响应其他命令
当redis通过SHUTDOWN指令接收到关闭服务器的请求时,会执行一个save命令,阻塞所有客户端,并在save命令执行完毕后关闭服务器
服务器自动触发
在redis.conf中设置save选项,redis会在save条件满足后自动触发一次BGSAVE命令,若设置多个save配置选项,当任意save选项满足时redis也会触发一次BGSAVE命令
1 | # Note: you can disable saving completely by commenting out all "save" lines. |
如上图所示 :keys 变化修改的频率越快(1->10->10000),快照自动保存的时间间隔越短(900->300->60)
AOF持久化
AOF 被称为追加模式,或日志模式,是 Redis 提供的另一种持久化策略,它能够存储 Redis 服务器已经执行过的的命令,并且只记录对内存有过修改的命令,这种数据记录方法,被叫做“增量复制”,其默认存储文件为appendonly.aof,每当有一个修改数据库的命令被执行时,服务器就将命令写入到 appendonly.aof 文件中,该文件存储了服务器执行过的所有修改命令(该操作同时也带了一些问题,例如重复记录旧的修改操作),因此只要服务器重新执行x一次 .aof 文件,就可以实现还原数据的目的,这个过程被形象地称之为“命令重演”。在AOF的配置中存在三种同步方式,它们分别是:
1 | appendfsync always |
AOF文件重写机制
AOF文件重写功能的实现原理为:首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令。
因为AOF文件重写会进行大量的文件写入操作,所以执行这个操作的线程将被长时间阻塞。Redis服务器使用单个线程来处理命令请求,所以如果由服务器进程直接执行这个操作,那么在重写AOF文件期间,服务器将无法处理客户端发送过来的命令请求。为了避免上述问题,Redis将AOF文件重写功能放到子进程里执行,这样做有以下2个好处:
- 子进程进行AOF文件重写期间,服务器进程(父进程)可以继续处理命令请求。
- 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性。
AOF后台重写的步骤如下所示:
- 服务器进程创建子进程,子进程开始AOF文件重写
- 从创建子进程开始,服务器进程执行的所有写命令不仅要写入AOF缓冲区,还要写入AOF重写缓冲区,写入AOF缓冲区的目的是为了同步到原有的AOF文件。写入AOF重写缓冲区的目的是因为子进程在进行AOF文件重写期间,服务器进程还在继续处理命令请求,而新的命令可能会对现有的数据库进行修改,从而使得服务器当前的数据库数据和重写后的AOF文件所保存的数据库数据不一致。
- 子进程完成AOF重写工作,向父进程发送一个信号,父进程在接收到该信号后,会执行以下操作:将AOF重写缓冲区中的所有内容写入到新AOF文件中,这样就保证了新AOF文件所保存的数据库数据和服务器当前的数据库数据是一致的;对新的AOF文件进行改名,原子地覆盖现有的AOF文件,完成新旧两个AOF文件的替换。
触发重写方式有两种:
客户端方式触发重写
执行BGREWRITEAOF命令,不会阻塞redis服务
Redis提供了BGREWRITEAOF命令来执行以上步骤,如下图所示:在执行完BGREWRITEAOF命令后,可以看到appendonly.aof文件的大小减少了,且aof中只保留了最后一条修改记录
1 | 127.0.0.1:6379> set club chelsa |
服务器配置方式自动触发
配置redis.conf中的auto-aof-rewrite-min-size和auto-aof-rewrite-percentage选项,该配置表示,当AOF文件的体积大于64MB,并且AOF文件的体积比上一次重写之后的体积大了至少一倍(100%),Redis将自动执行BGREWRITEAOF命令,如果重写过于频繁,可以考虑调大rewrite-percentage:
1 | # This base size is compared to the current size. If the current size is |
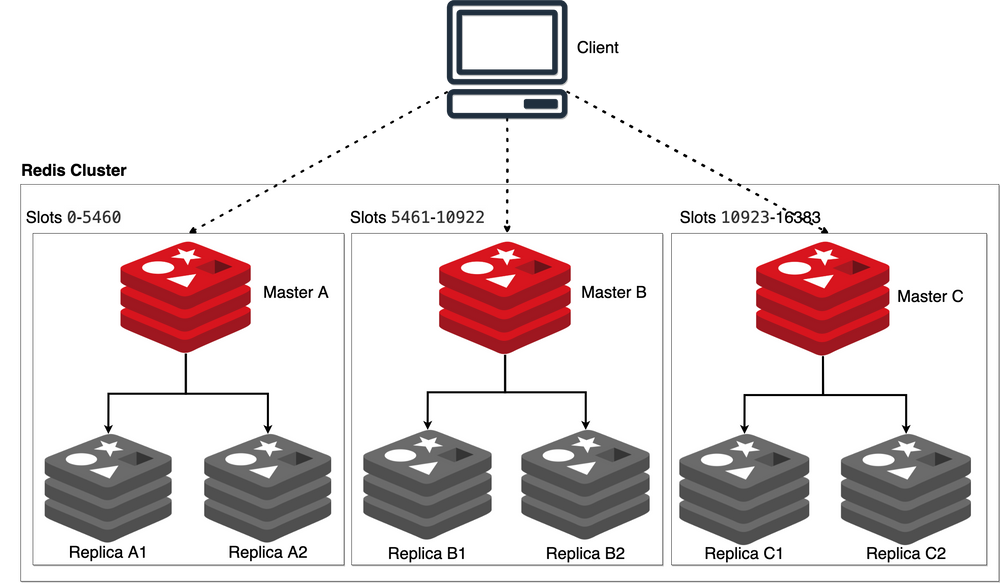
Redis分布式缓存
本地缓存:存储在应用服务器内存中的数据称之为本地缓存(local cache)
分布式缓存:存储在当前应用服务器内存之外的数据称之为分布式缓存(distributed cache)
集群:将提供同一种服务的多个节点放在一起共同对系统提供该服务,这多个节点称之=为集群
分布式集群:有多个不同服务集群共同对系统提供多服务,且独立于服务器之外
Mybatis二级缓存
可利用mybatis自身本地缓存结合redis实现分布式缓存,因此需要先了解一下mybatis自身缓存机制,mybaits提供一级缓存,和二级缓存:
(1)一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。Mybatis默认开启一级缓存。
(2)二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。
(3)sqlSessionFactory层面上的二级缓存默认是不开启的,二级缓存的开启需要进行配置,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。 也就是要求实现Serializable接口,**只需要在映射XML文件配置就可以开启二级缓存了
- 映射语句文件中的所有select语句将会被缓存。
- 映射语句文件中的所有insert、update和delete语句会刷新缓存。
- 缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表,比如No Flush Interval,(CNFI没有刷新间隔),缓存不会以任何时间顺序来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
- 缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
下面简单测试一下二级缓存(使用Mybatis缓存机制必须序列化实体类,即implements Serializable):
- 在UserMapper.xml中设置
标签,即
1 | <mapper namespace="com.lzc.study.mapper.UserMapper"> |
- 添加测试方法
1 |
|
日志输出如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
212023-01-01 21:05:48.804 INFO 13168 --- [ main] com.lzc.study.TestUser : Started TestUser in 1.894 seconds (JVM running for 2.485)
2023-01-01 21:05:49.158 INFO 13168 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
2023-01-01 21:05:49.386 DEBUG 13168 --- [ main] com.lzc.study.mapper.UserMapper : Cache Hit Ratio [com.lzc.study.mapper.UserMapper]: 0.0
2023-01-01 21:05:49.394 DEBUG 13168 --- [ main] com.lzc.study.mapper.UserMapper.findAll : ==>
`Preparing: select uid,uname,address from user`
2023-01-01 21:05:49.414 DEBUG 13168 --- [ main] com.lzc.study.mapper.UserMapper.findAll : ==> Parameters:
2023-01-01 21:05:49.431 DEBUG 13168 --- [ main] com.lzc.study.mapper.UserMapper.findAll : <== Total: 4
User(uid=1, uname=Owen, address=England, uage=null)
User(uid=7, uname=Sonny, address=Korea, uage=null)
User(uid=9, uname=Benzema, address=france, uage=null)
User(uid=10, uname=kane, address=England, uage=null)
========================
2023-01-01 21:05:49.440 WARN 13168 --- [ main] o.apache.ibatis.io.SerialFilterChecker : As you are using functionality that deserializes object streams, it is recommended to define the JEP-290 serial filter. Please refer to https://docs.oracle.com/pls/topic/lookup?ctx=javase15&id=GUID-8296D8E8-2B93-4B9A-856E-0A65AF9B8C66
2023-01-01 21:05:49.441 DEBUG 13168 --- [ main] com.lzc.study.mapper.UserMapper : Cache Hit Ratio [com.lzc.study.mapper.UserMapper]: 0.5
User(uid=1, uname=Owen, address=England, uage=null)
User(uid=7, uname=Sonny, address=Korea, uage=null)
User(uid=9, uname=Benzema, address=france, uage=null)
User(uid=10, uname=kane, address=England, uage=null)通过日志输出可以看出来:第二次查询前显示击中缓存(
Cache Hit Ratio),因此第二次调用findAll()并不会输出查询语句
自定义RedisCache
mybatis默认cache实现是通过实现Cache接口,因此可以自定义RedisCache类并实现Cache接口类中的方法,然后在Mapper.xml中应用RedisCache:
重写Cache类中方法
(1) 首先需要自定义工具类来获取spring工厂中的redisTemplate
1 | package com.lzc.study.util; |
(2)然后重写putobject()方法:
1 | //缓存中放值 ApplicationContext context.getbean("redisTemplate") |
这样设置后可以在redis中成功存放值

(3)重写getObject()方法:
1 |
|
(4)再次测试查询方法后,会发现console不会输出任何查询语句(因为结果已经存储在redis中了,不会再访问mysql)
1 | 2023-01-01 22:27:57.405 INFO 19300 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited |
注意!!! 上述方法只涉及到查询,如果涉及到insert、update、delete操作时,则会先调用redisCache中自定义的clear()来清空缓存数据,避免以后直接查询出来的数据是错误数据
(5)通过重写Cache类中的clear()方法来清空缓存:
1 |
|
测试清空缓存
调用自定义的saveUser()方法后会发现redis中存储的hashkey自动清除:
1 | <!--新增用户--> |
1 | public void saveUser() |

存在问题及解决方法
然而这种根据mapper的namespace(Cache中所定义的 private final String id;)来清空缓存的方法存在一定缺陷:假如有UserMapper,ProductMapper多个Mapper,UserMapper中定义了findAll()、findNameAge(),那么缓存在redis中的Hash的大Key为com.lzc.study.mapper.UserMapper(对应的namespace),该哈希表下分别存储了,com.lzc.study.mapper.UserMapper.findAll和``com.lzc.study.mapper.UserMapper.findNameAddress`两个小key,对应value即为各自的查询结果。
这样就暴露出一个问题:假如项目中涉及到多表关联(User表和Product表存在一定联系),如果只对数据库中某张表执行增删改操作,那么对应地只会清空对应Mapper类查询方法的缓存,而不会清空ProductMapper类对应的redis缓存,这样存储在redis中的ProductMapper缓存中的数据就失去参考价值了,解决方法是在Mapper.xml中设置以下标签:
1 | <cache-ref namespace="com.lzc.study.mapper.UserMapper"/> |
在ProductMapper.xml中关联UserMapper的缓存(反过来也行),这样一旦涉及到某一方的查询方法,不仅会清空当前Mapper所对应的缓存,同时还会清空所有引用方Mapper的缓存,实现多个Mapper在redis中的缓存共享