视频分割
主要分为以下三种:
Video Object Segmentation(视频对象分割):从视频所有图像帧中把感兴趣的物体区域的分割出来, 主要数据集有 DAVIS、Youtube-VOS(Video Object Segmentation)、Youtube-VIS(Video Instance Segmentation)
Video Semantic Segmentation(视频语义分割):相对于视频物体分割,VSS需要对每个像素点均给出一个类别预测,主要数据集有 Cityscapes、NYUv2、CamVid、VSPW(CVPR2021)
Video Panoptic Segmentation(视频全景分割):需要把同一类的不同物体均区分出来,而语义分割只需要区分出不同类别,数据集有Cityscapes
视频语义分割
目前视频语义分割主要研究的重点大致有两个方向:第一个是如何利用视频帧之间的时序信息来提高图像分割的精度,第二个是如何利用帧之间的相似性来减少模型计算量,提高模型的运行速度和吞吐量。视频分割任务的评估指标和图像语义分割相同均为mIOU(mean Intersection-over-Union),由于是video数据,同时会测试模型的FPS作为video加速方向的一个平衡:
利用时序信息提高精度方向
该方向主要是利用视频的时序信息进而获得语义信息一致性更强的特征来做分割
(1)Semantic Video CNNs through Representation Warping(ICCV 2017)
该文章提出了NetWarp结构,它的主要作用是利用光流把前一帧的特征搬移到当前帧,进而起到一定程度上特征增强的作用,其中光流定义为两张图像之间对应像素移动的向量,这个结构可以插入到视频的帧与帧之间,模块的具体操作如下图所示,模型的输入是两张连续的帧,(t-1)代表前一帧,t代表当前帧,第一步是计算两帧之间的光流F(t),这里的光流计算是采用offline的形式,即每个光流是提前计算好的,具体的光流的计算方法为Dis-Flow。接着把光流和两帧图像送入到一个叫做Transform Flow的模块中,这个模块是有小的全卷积网络模块组成,其设计目的是用图像信息来补充光流信息(相对Dis-Flow,Transform Flow包含了物体的细节信息),之后用transform flow再把前一帧的特征warp到当前帧(warp的具体实现是采用双线性插值操作,是根据当前帧的特征点由光流信息找到对应的前一帧的特征点,再把特征点拿过来,之后介绍很多工作都会用到这种操作)。最后结合当前帧和之前帧的信息得到最终的特征表示。
(2)Semantic Video Segmentation by Gated Recurrent Flow Propagation(CVPR 2016)
这篇文章工作是结合多帧未标注的信息来提高分割的性能,文章提出一个叫做Spatio-Temporal Transformer GRU 的模块,不同于上篇文章中的对特征进行操作,这里作者只是对分割后的结果进行操作,通过结合不同时间维度上的结果来指导图像分割网络的学习。下图中的Spatio-Temporal Transformer GRU(STGRU)本质上也是通过光流信息把前后帧的label map结合到当前帧t。考虑到前面帧的一些信息对当前帧的分割并没有太大的帮助,比如一些车的部位在前几帧并没有出现,即使通过光流flow把它移动到当前帧,但是这些信息对于当前帧的分割是没有帮助的。 所以作者使用了gate的思想让网络学习去combine不同的语义图,这里他使用了convolution GRU 来融合不同时间点的信息,convolution GRU是具体操作是利用卷积来学习临近帧的局部信息,所以它可以更好融合不同的位置的语义表示.这里光流产生网络采用了flownet2,是一种online计算光流的方式,这样整个frame work可以进行端到端地训练和学习。
其中STGRU的具体计算过程如下:首先对于临近的两帧计算出其光流Flow以及两帧各自语义分割后的结果,然后利用光流把前一帧的结果warp 到当前帧,最后把warp后的结果和当前帧的分割信息一同送入到GRU的模块中,得到一个输出作为当前帧的分割结果。如图中所示,前帧的路灯(灰色)通过STGRU模块计算之后就把信息传递到了当前帧,这样就弥补了当前帧分割不准的情况。
整个框架就是把STGRU插入到图像语义分割网络中,对于当前帧,会考虑把前面后面的多个帧作为输入,从前后各采样一帧,计算sample的帧和当前帧的光流,并把多帧的语义分割图通过Convolution GRU从前向后以及从后向前地传递到当前帧(此时会有两个STGRU模块,下图中的gf和gb),最终得到一个融合具有双向temporal信息的特征表示,这时再去计算Loss进行反传。在训练的时候,作者首先会去训练图像语义分割网络,之后把Flownet的参数固定后,再去fine tune (微调)STGRU和语义分割网络,从某种意义上讲,这个框架就是学习如何把时序上多帧信息融合的更好。
上述两篇文章中都用到了没有标注的video数据(半监督学习),都是用光流信息来把特征或者语义图进行融合获取更好的特征表示。
降低视频冗余计算量方向
由于在视频中帧和帧之间的相似度极高,如果像图像那样一帧一帧地送入神经网络中势必会带来很多冗余的计算量,而在一些具体的应用如自动驾驶任务上,模型运行的速度也是一个重要因素,因此近些年来有很多工作在研究视频分割加速。
(1) Deep Feature Flow for Video Recognition (CVPR 2017)
Deep Feature Flow是近些年来视频任务的代表作之一,文章的出发点是在video中deep feature的帧间差异性比较小,而对于每一帧而言,获取deep feature的时间和计算的成本特别地大(尤其是一些深度网络),作者考虑用光流来把前面的特征给warp到当前帧,进而减少计算量。
在目标检测和语义分割任务中,通用的做法是首先将图片送到一个深层卷积网络提取特征,再将特征送入相应的任务网络得到结果。在视频上进行目标检测或者语义分割任务时,如果继续使用单帧图片的方法,将有大量的时间耗在特征提取上面,无法做到实时性。而由于视频的连续性,相邻两帧的feature map其实具有很高相似度,这里作者通过可视化resnet101最后一个卷积层里面的两个卷积核输出的特征来进行了验证。
如上图所示:第一排和第二排分别是同一视频中的相邻的两帧,第一列是原始图片,后两列是可视化之后的卷积特征,可以看到上下两排卷积特征非常相似。同时卷积特征与图像内容保持了空间的对应性,可以看到中间的特征图上激活的汽车特征的位置和原始图片上汽车的位置是对应的,而这种对应性能够提供使用空间warp,将临近帧的特征进行轻量传播,以此来避免在每一帧上都进行特征提取。这里作者使用了光流信息进行特征传播,将第一帧的特征fk与两帧的光流Mi→k结合,warp得到第二帧的特征估计fk→i。第三排就是warp得到的结果,与CNN计算的真实效果,也就是第二排差不多。通常光流估计和特征传播比卷积特征的计算快得多,能够实现显著的加速。
- 什么是warp操作?
warp最开始是用在对图片像素点进行对齐的操作。光流本质就是记录了某帧图片上的像素点到另一帧的运动场,光流图上每一个点对应着图片上该点的二位运动矢量。假设我们知道第t帧中的点P会运动到第t+1帧,这样就得到了运动矢量。这时如果我们已知第t帧的像素值和第t+1帧每个像素点的运动矢量,则可倒推出t+1帧上的任一点在第t帧的位置,则可以通过双线性插值来得到对应的点的像素值。由于光流值通常不是整数值,因此用双线性插值。
deep feature flow算法

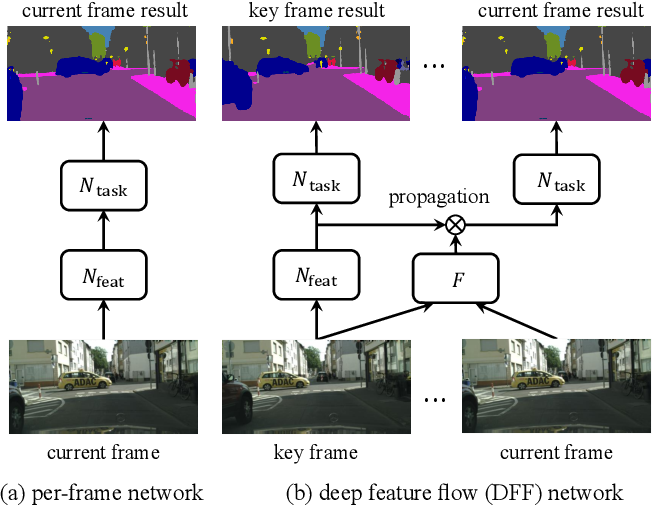
文章中将目标检测或者语义分割网络分解成两个连续的子网络,Nfeat是特征网络,一般用resnet,Ntask是任务网络,在特征图上进行语义分割或者目标检测任务。图中的F是光流估计网络,这里用的是改造过的flownet,输入相邻的两帧图片,得到和feature map大小一样的特征光流图,flownet已经在光流估计的数据集上预训练过。DFF在一段视频帧里面以固定间隔选取关键帧,其他的帧为非关键帧。对于关键帧,DFF用一个特征提取网络去提取feature map,进而任务网络以这些特征为输入得到结果;对于非关键帧,DFF先经过光流网络计算该非关键帧与此之前最近的关键帧的特征光流图,然后利用得到的光流图和关键帧的feature map进行warp操作,从而将关键帧的特征对齐并传播到该非关键帧,然后任务网络基于此特征输出该非关键帧的任务结果。DFF利用相对轻量的光流网络和warp操作代替原来的特征提取网络来得到相应的特征,达到节省计算量来加速的目的。
(另一种理解)DFF首先会选取一个帧叫做关键帧(key frame),这里key frame的意思是让当前的帧图像通过网络卷积获取深度特征(deep feature),而对于不是key frame的帧,会去计算它与关键帧之间的光流(这里通过flownet-s),然后再用光流把关键帧的深度特征图warp到当前帧,得到当前帧的分割结果,进而求得loss进行反向传播。这里key frame的选取是固定的,每隔k个选择一个作为key frame。由于光流网络比较浅并且计算量上远小于分割网络,所以这样可以大大提高分割的速度。
DFF作为视频语义分割加速方面的一个开山之作,后面有很多工作都是基于这个框架展开的。
(2)Low-Latency Video Semantic Segmentation(CVPR 2018)
DFF的关键帧选择是固定的,那么如何更加自适应地选择关键帧呢?这篇文章给出的答案是参考低层次特征(low level feature)。这篇文章的出发点是low level features的变化一定程度地代表了是否要选择key frame,因为如果帧的内容发生巨大的变化的话,底层特征比如边缘位置信息的差异性一定会很大,为此作者还做了实验来分析,作者在Cityscape和Camvid上观察发现底层特征的差异性越大,帧的内容的差异性就会变大。第二个创新点是在warp deep feature操作时不采用光流而是用卷积的形式把之前的deep feature给移动当前帧,并且同时结合当前帧的low-level feature。这里的Base Network选择的是PSP net。
上图中S(l)代表网络抽出底层特征(low level feature),S(h)代表获得深度特征(deep feature),在实现上可以认为是同一个网络的两个不同的阶段,对于每一张新进来的帧,都会通过S(l)获取底层特征,然后把当前帧的底层特征和之前key frame的底层特征送入到一个小的FCN网络来预测一个值(文章中叫做weight predictor,下图),这个值代表当前帧是否为key frame的可能性,如果超过一个阈值的话就会输出1,表示当前帧的内容和之前的差距比较大,选择为关键帧,否则输出为0,代表不是关键帧,这个小的FCN可以自适应地学习出来每一帧做为关键帧的重要性。
对于关键帧,会像DFF那样把底层特征继续经过S(h)得到deep feature。对于非关键帧,作者用另一个小的FCN(上图中的Weight Predictor)来把预测一个权重,这个权重W是一个KKwh的tensor,代表对于key frame上每一点到当前帧都有一个KK的卷积核,之后通过卷积的方式把之前的deep feature给wrap过来,从图10中可以看到Weight Predictor可以把深度语义特征很好地移动到下一帧。最后再把当前帧的low level feature和warp后的deep feature进行融合作为当前帧的输出。
相比于DFF,这篇工作考虑了low level feature,显著地提高分割的结果,并且在速度上提出一种Low latency的调度的策略来进一步加速,这个策略是在计算关键帧的特征时候,可以先用一个进程用feature warp的方式计算一个fake的deep feature,另一个进程仍然计算关键帧的deep feature,之后非关键帧用这个fake的deep feature进行计算,但是当真的进程计算完毕后会把这个fake的deep feature 替换掉,让接下来的非关键帧使用这个真正的deep feature 得到输出结果,这种策略以牺牲一定精度的形式换取速度上的提升。