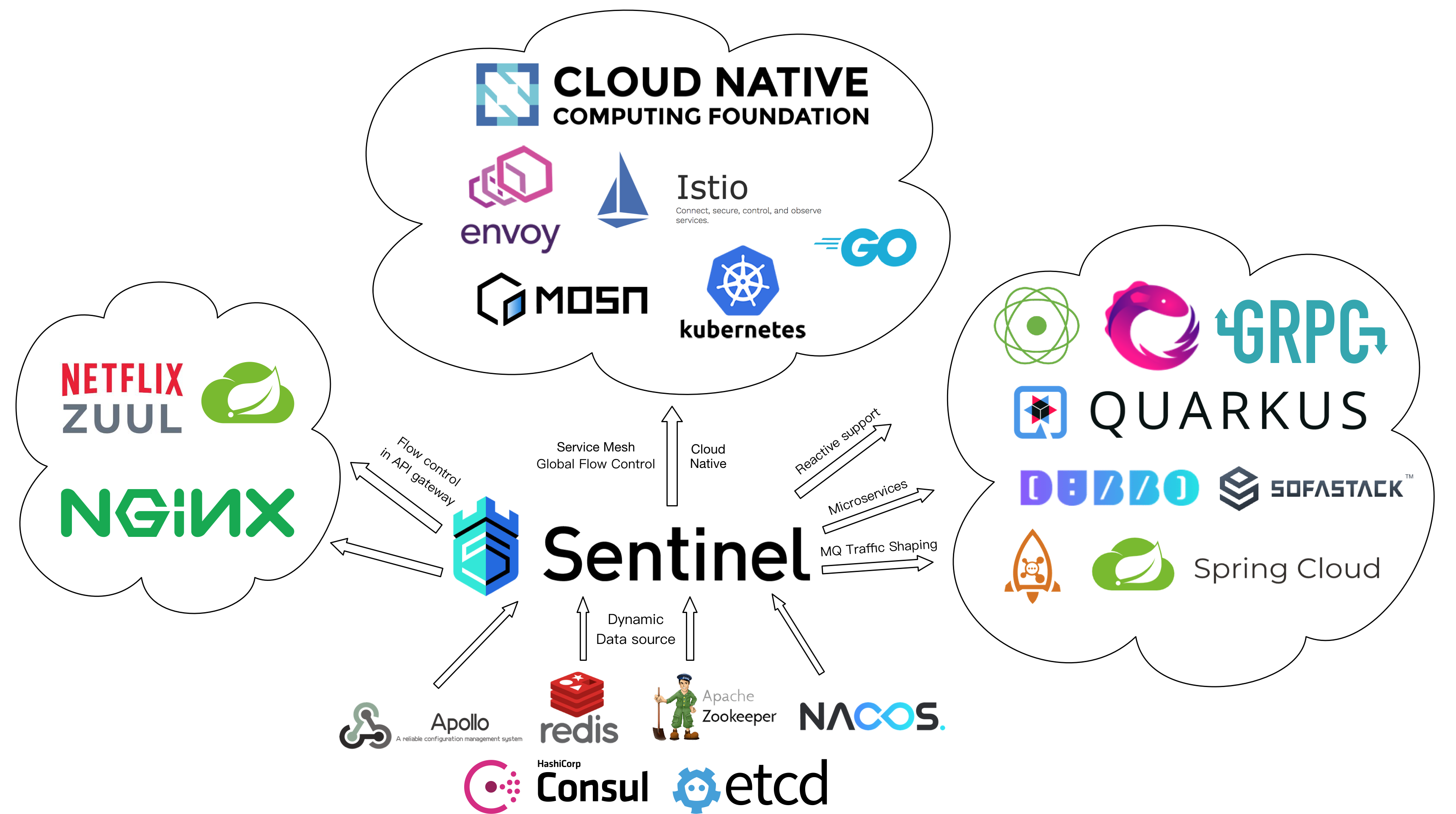
SpringCloud Gateway
网关简介
在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢? 如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去用。
这样的架构,会存在着诸多的问题:
- 每个业务都会需要鉴权、限流、权限校验、跨域等逻辑,如果每个业务都各自为战,自己造轮子实现一遍,会 很蛋疼,完全可以抽出来,放到一个统一的地方去做
- 如果业务量比较简单的话,这种方式前期不会有什么问题,但随着业务越来越复杂,比如淘宝、亚马逊打开一 个页面可能会涉及到数百个微服务协同工作,如果每一个微服务都分配一个域名的话,一方面客户端代码会很难维护,涉及到数百个域名,另一方面是连接数的瓶颈,想象一下你打开一个APP,通过抓包发现涉及到了数百个远程 调用,这在移动端下会显得非常低效
- 后期如果需要对微服务进行重构的话,也会变的非常麻烦,需要客户端配合你一起进行改造,比如商品服务, 随着业务变的越来越复杂,后期需要进行拆分成多个微服务,这个时候对外提供的服务也需要拆分成多个,同时需要客户端配合进行改造
Spring Cloud Gateway 是Spring Cloud官方推出的第二代网关框架,定位于取代 Netflix Zuul1.0。相比 Zuul 来说,Spring Cloud Gateway 提供更优秀的性能,更强大的有功能
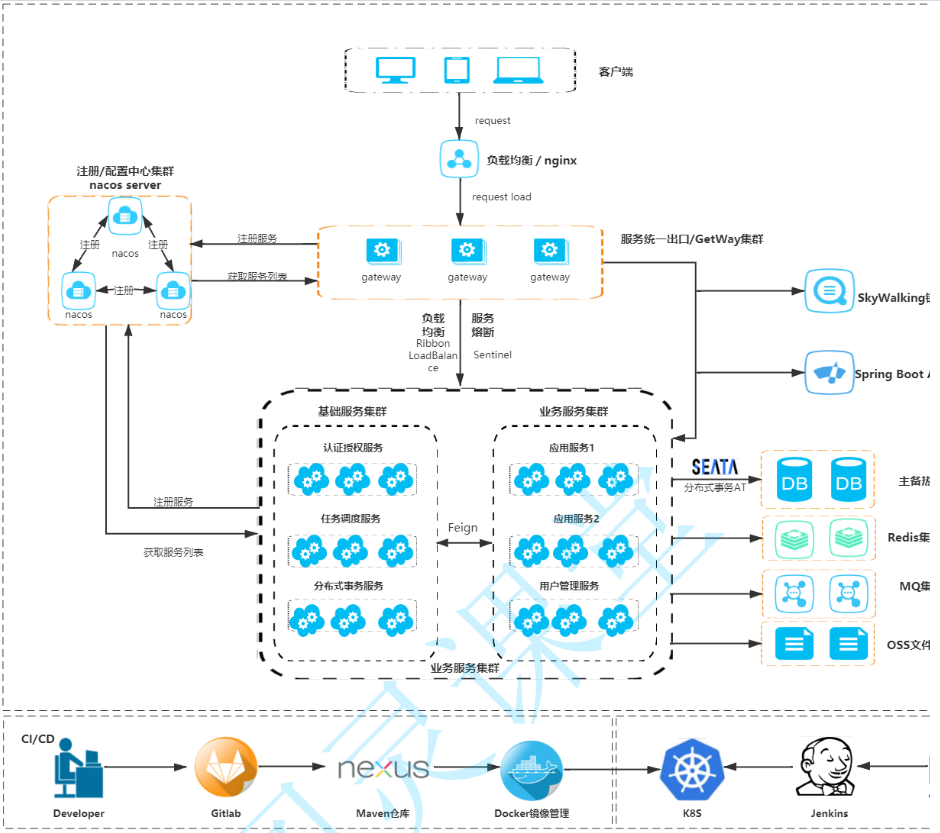
使用SpringGateway后的整体架构图如下:
功能特征
基于Spring Framework 5, Project Reactor 和 Spring Boot 2.0 进行构建;
动态路由:能够匹配任何请求属性; 支持路径重写;
集成 Spring Cloud 服务发现功能(Nacos、Eruka);
可集成流控降级功能(Sentinel、Hystrix);
可以对路由指定易于编写的 Predicate(断言)和 Filter(过滤器);
(1)路由(route)
路由是网关中最基础的部分,路由信息包括一个ID、一个目的URI、一组断言工厂、一组Filter组成。如果断言为真,则说明请求的URL和 配置的路由匹配。
(2)断言(predicates)
Java8中的断言函数,SpringCloud Gateway中的断言函数类型是Spring5.0框架中的ServerWebExchange。断言函数允许开发者去定义 匹配Http request中的任何信息,比如请求头和参数等
(3)过滤器(Filter)
SpringCloud Gateway中的filter分为Gateway FilIer和Global Filter。Filter可以对请求和响应进行处理
环境搭建
(1)引入依赖并编写yaml配置文件:
1 | <!--添加gateway依赖--> |
1 | server: |
(2)通过postman发送请求:http://localhost:8088/order-service/order/findId后,得到结果-库存id为9
集成Nacos
同样的先添加nacos依赖:
1 | <!--添加nacos依赖--> |
然后修改yaml配置文件:
1 | nacos: |
简易配置方法(不推荐)
1 | server: |
内置过滤器(局部)
Gateway内置了很多的过滤器工厂,我们通过一些过滤器工厂可以进行一些业务逻辑处理,比如添加剔除响应头,添加去除参数等
在gateway的application.yaml中添加此参数(设置RequestHeader)
1 | filters: |
然后在OrderController中添加测试方法:
1 |
|
自定义局部过滤器
自定义Filter需要继承AbstractNameValueGatewayFilterFactory,且自定义名称必须要以GatewayFilterFactory结尾并交给spring管理:
全局过滤器
局部过滤器和全局过滤器区别:
局部:局部针对某个路由, 需要在路由中进行配置
全局:针对所有路由请求, 一旦定义就会投入使用
Seata
事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。在关系数据库中,一个事务由一组SQL语句组成。事务应该具有4个属性:原子性、一致性、隔离性、持久性。 这四个属性通常称为ACID特性:
(1)原子性(atomicity):个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
(2)一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态,事务的中间状态不能被观察到的
(3)隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。隔离性又分为四个级别:读 未提交(read uncommitted)、读已提交(read committed,解决脏读)、可重复读(repeatable read,解决虚读)、串行化(serializable,解决幻读)
(4)持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。任何事务机制在实现时,都应该考虑事务的ACID特性,包括:本地事务、分布式事务,即使不能都很好的满足,也要考虑支持到什么程度
@Transational
大多数场景下,我们的应用都只需要操作单一的数据库,这种情况下的事务称之为本地事务 (Local Transaction)。本地事务的ACID特性是数据库直接提供支持,在JDBC编程中,我们通过java.sql.Connection对象来开启、关闭或者提交事务
分布式事务
解决分布式事务,也有相应的规范和协议,分布式事务相关的协议有2PC、3PC。由于三阶段提交协议3PC非常难实现,目前市面主流的分布式事务解决方案都是基于2PC协议(Two-phase commit)实现的,常见分布式事务解决方案
1、seata 阿里分布式事务框架 (Auto Transaction)
2、消息队列mq(Try Confirm Cancel)
3、saga
4、XA
他们有一个共同点,都是“两阶段(2PC)”,“两阶段”是指完成整个分布式事务,划分成两个步骤完成;
实际上,这四种常见的分布式事务解决方案,分别对应着分布式事务的四种模式:AT、TCC、Saga、XA;
四种分布式事务模式,都有各自的理论基础,分别在不同的时间被提出;每种模式都有它的适用场景,同样每个模式也都诞生有各自的代表产品;而这些代表产品,可能就是我们常见的(全局事务、 基于可靠消息、最大努力通知、TCC)。
2PC两阶段提交协议
Prepare(提交事务请求)
询问:协调者向所有参与者发送事务请求,询问是否可执行事务操作,然后等待各个参与者的响应。
执行:各个参与者接收到协调者事务请求后,执行事务操作(例如更新一个关系型数据库表中的记录),并将 Undo 和 Redo 信息记录事务日志中。
响应:如果参与者成功执行了事务并写入 Undo 和 Redo 信息,则向协调者返回 YES 响应,否则返回 NO 响应。当然,参与者也可能宕机,从而不会返回响应(类似Rocketmq中的思想————消息生产者先在本地检测事务状态,然后返回结果给Broker(消息服务器集群)。
Commit(执行事务提交)
执行事务提交分为两种情况,正常提交和回退。
(1)正常提交事务:
- commit请求:协调者向所有参与者发送 Commit 请求。
- 事务提交: 参与者收到 Commit 请求后,执行事务提交,提交完成后释放事务执行期占用的所有资源。
- 反馈结果: 参与者执行事务提交后向协调者发送 Ack 响应。
- 完成事务: 接收到所有参与者的 Ack 响应后,完成事务提交。
(2)中断事务:
在执行Prepare步骤过程中,如果某些参与者执行事务失败、宕机或与协调者之间的网络中断,那么协调者就无法收到所有参与者的 YES 响应,或者某个参与者返回了 No 响应,此时,协调者就会进入回退流程,对事务进行回退。
- rollback请求: 协调者向所有参与者发送 Rollback 请求(一个参与者失败需要所有参与者进行rollback保持数据一致性)。
- 事务回滚: 参与者收到 Rollback后,使用Prepare阶段的 Undo 日志执行事务回滚,完成后释放事务执行期占用的所有资源。
- 反馈结果: 参与者执行事务回滚后向协调者发送 Ack 响应。
- 中断事务: 接收到所有参与者的 Ack 响应后,完成事务中断。
2PC的问题
- 同步阻塞: 参与者在等待协调者的指令时,其实是在等待其他参与者的响应,在此过程中,参与者是无法进 行其他操作的,也就是阻塞了其运行。 倘若参与者与协调者之间网络异常导致参与者一直收不到协调者信 息,那么会导致参与者一直阻塞下去
- 单点故障问题: 在
2PC中,一切请求都来自协调者,所以协调者的地位是至关重要的,如果协调者宕机,那么就会使参与者一直阻塞并一直占用事务资源。 如果协调者也是分布式,使用选主方式提供服务,那么在一个协调者挂掉后,可以选取另一个协调者继续后续的服务,可以解决单点问题。但是,新协调者无法知道上一个事务的全部状态信息(例如已等待 Prepare 响应的时长等),所以也无法顺利处理上一个事务 - 数据不一致性问题:在
Commit事务过程中,Commit 请求/Rollback 请求可能因为协调者宕机或协调者与参与者网络问题丢失,那么就导致了部分参与者没有收到 Commit/Rollback 请求,而其他参与者则正常收到执行了 Commit/Rollback 操作,没有收到请求的参与者则继续阻塞。这时,参与者之间的数据就不再一致了
Seata Server
Server端存储模式(store.mode)支持三种:
- file:(默认)单机模式,全局事务会话信息在内存中读写,并持久化本地文件
root.data(./bin/sessionStore/root.data),性能较高(默认) - db:(5.7+)高可用模式,全局事务会话信息通过db共享,相应性能差些
- redis模式:采用redis 会话信息,Seata 1.4 以后支持的新模式,性能较高但存在事务丢失风险
环境搭建
1.本实验采取db模式进行测试,首先修改conf/file.conf文件,内容如下:
1 | ## database store property |
,然后在datagrip下执行官方的建表sql语句
2.将Seata Server注册到Nacos:
(1)修改conf/registry.conf文件(分配设置注册中心与配置中心):
1 | #注册中心 |
(2)还要修改script/config-center/config.txt,将该config里的数据源也改为db(该文件可在这里下载):
1 | #Transaction storage configuration, only for the server. The file, db, and redis configuration values are optional. |
(3)将修改后的配置文件里的配置信息注册到nacos:
打开D:\Code\seata\script\config-center\nacos目录,运行nacos-config.sh(前提已经安装git)
(4)打开nacos网页控制台(http://192.168.1.107:8848/nacos/index.html),可以发现配置已经成功导入了:

后面再启动seata发现连不上了。。。 原因目前还没找到,连接池换了也不行,感觉应该是版本过高问题导致的