打卡业务总览 关键词
打卡业务中经常涉及到的关键词如下:
关键词 说明 示例
打卡规则 打卡规则 主要是约束用户可打卡的方式:外勤打卡、内勤打卡;租户办公位置的gps或wifi信息(用来判断是否是有效打卡);打卡动作的约束限制:是否需要附件、是否需要拍照等,目前打卡规则的配置是依附于考勤组规则配置页面
打卡渠道 打卡渠道是用来标识用户使用的是哪种渠道进行的打卡动作数据来源的主要渠道:拉取第三方: 企微、钉钉(钉钉打卡、钉钉签到)、飞书Moka打卡:moka移动端打卡考勤机打卡: 中控、天敏考勤机第三方主动上报: 使用openApi主动上报
打卡成功提示 打卡成功后,给用户发送打卡动作操作成功的提醒通知
员工打卡提醒 在上班时间范围和下班时间范围内主动发送通知,提醒用户进行打卡操作配置项:考勤组中设置上、下班的提醒时间(在班次前后多久)
例如设置的班次时间为9点~18点 :则上班打卡提醒:打卡前10分钟, 下班打卡提醒:下班后5分钟上班提醒通知发送时间:8点50分下班提醒通知发送时间:18点05分
打卡方式 内勤打卡:在租户办公点有效范围内的打卡行为属于内勤打卡外勤打卡:不在租户办公点有效范围内的打卡行为属于外勤打卡
系统卡(免打卡) 免打卡场景下,考勤核算在触发核算时给用户自动生成的打卡记录被称为系统卡
入、离职日免打卡请假免打卡外出免打卡出差免打卡入口:考勤组设置
自动打卡 为了提高用户打卡成功率,用户进入打卡页面时根据规则可能会主动触发一次自动打卡1. 如果是有效上班打卡范围内,需要check范围内是否已经有过打卡记录,没有打卡记录的才会触发自动打卡 2. 如果在有效下班打卡范围内,进入页面就会触发一次自动打卡有效上班打卡范围: 标准上班打卡范围开始时间 ~ 弹性工作开始时间 有效下班打卡范围: 弹性工作结束时间 ~标准签退打卡范围结束时间
班次时间9点18点,有效打卡范围 7点20点上班卡:用户在7点9点进入打卡页面,期间7点9点如果没有打卡记录,进入页面会触发自动打卡下班卡:用户在18点20点进入打卡页面,会触发自动打卡班次时间,需要考虑到弹性时间,比如允许晚到晚走30分钟,则上班卡自动打卡时间会变为7点9点30(上班卡时间会考虑晚到晚走规则) ;上班打卡是8点半,则下班自动打卡开始时间为17点30
数据库表 打卡通用规则表:
表名
说明
备注
hcm_abs_attendance_rule_gps
考勤规则中用于打卡的GPS位置表
hcm_abs_attendance_rule_wifi
考勤规则中用于打卡的WiFi信息表
hcm_ding_user
钉钉同步的用户表
hcm_abs_ding_talk_clock_record
钉钉同步的打卡记录表
hcm_abs_clock_in_record
所有来源汇总的打卡记录表
hcm_abs_moka_clock_record
移动端打卡记录表
hcm_abs_sync_clock_record
同步记录表
hcm_abs_ding_talk_sync_log
钉钉同步操作的日志表
hcm_excel_templateexcel模板信息表
公共的模块,不独属于clock,无需迁移
三方打卡记录常用的数据库表:
常用数据库表:
以下和员工相关联的表都可以通过employeeId去查询对应的映射关系
数据库表
含义
hcm_ding_ent
租户在钉钉和people的映射关系
hcm_ding_user
员工在钉钉和people的映射关系
hcm_ding_talk_clock_record
员工在钉钉打卡的原始记录
hcm_wxin_ent
员工在企业微信和people的映射关系
hcm_wxin_user
员工在企业微信和people的映射关系
hcm_wxin_origin_clock_record
员工在企业微信的原始记录
hcm_lark_ent
员工在飞书和people的映射关系
hcm_lark_user
员工在飞书和people的映射关系
hcm_abs_lark_origin_clock_record
员工在飞书的原始记录
关键流程图 1、整体业务逻辑
2、移动端打卡
3、手动导入打卡记录
4、同步钉钉打卡
5、企业微信打卡
6、获取打卡记录
7、三方打卡记录交互流程
打卡数据同步 打卡数据同步的总体服务架构图如下所示:
1、同步三方渠道打卡数据:exclamation: 而针对三方渠道打卡的数据拉取环节 ,流程如下所示:
注意这里有几个要点:exclamation: :exclamation:
transId的作用: 调用mobile获取打卡数据→ mobile返回打卡数据 是通过mq消息的方式触发的异步回调,由于三方人数+频次+时间区间的限制,一次调用可能会有多次的mq回调,transId的作用主要是用来识别某一批的拉取数据已经全部处理完成。构建一个transId为key,value为员工列表的set, 每次回调取出transId, 并删除回调数据中在set中的人员数据。如果transId的set为空,本次同步任务可以认为已结束
由于各个渠道目前对拉取频率限制不一样,并且考虑到一个渠道不能影响其他渠道的拉取,定时任务是分渠道进行的配置
各个渠道对历史是否已经处理过相同的打卡记录的判断方式是不一样的:如果三方有唯一性标识,则使用唯一性标识,如果没有则使用用户名+时间构成唯一性标识 , 目前飞书用的是外部唯一标识
中控考勤机由于在数据回写过程中的流程和三方渠道类似,所以也是采用的这种类似方式:将调用mobile的数据拉取接口更换为调用中控服务地址;数据拉取到后,将数据构造成mobile的打卡数据内容,发送到同topic下。后续卡数据处理流程一致
问题:
三方渠道的打卡时间在落打卡记录表时,被抹去了秒→ 导致的问题:用户如果在相同分钟,不同秒时间下,如果进行了多次打卡,在moka系统上,无法体现秒级别
三方渠道通常都会有自己的限流措施,这样就会有一个矛盾点:同步任务频率大(周期短),用户的打卡数据就更实时,但是触发接口限流的几率就会很大→ 解决思路:如果三方渠道支持数据回调,需要接入回调。回调作为主,定时任务作为数据拉取的备用。
下面我们对着代码走一遍流程,看看是如何指定打卡渠道,并同步该渠道的数据:
代码入口在: hcm-absence-clock下的SyncClockInRecordController.java下:
1、在页面点击打卡数据同步时,可以选择多个渠道,比如数据来源选择 同步飞书:
可以看到 clockInChannel的value值为3 ,说明每一个clockChannel均关联一个特定的渠道,我们走入打卡的入口url(/api/abs/clock/v1/channel/record/sync)也可以看到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @ApiOperation("同步渠道打卡数据") @PostMapping("/sync") ResultDto<Void> sync (@RequestBody @Validated ApiSyncClockInDataParamDto param, @ApiIgnore CurrentUserDto currentUser) { if (param.getStartDate().after(param.getEndDate())) { throw new CustomException (ErrorCodeEnum.INVALID_PARAMS.getCode(), "开始时间不能小于结束时间" ); } Long entId = currentUser.getEntId(); Long buId = currentUser.getBuid(); SyncTypeEnum syncClockInChannel = param.getClockInChannel(); boolean isThirdChannel = isThirdChannel(syncClockInChannel); if (isThirdChannel) { List<EntCheckInChannelDto> entCheckInChannelDtoList = hcmAbsenceClockSyncServiceAdapter.list3rdCheckInEnt(entId, buId, false ); boolean notValidChannel = !isValidThirdChannel(entCheckInChannelDtoList, syncClockInChannel); if (notValidChannel) { String syncClockInChannelDesc = syncClockInChannel.getDesc(); log.error("企业未开通" + syncClockInChannelDesc + "或未开启" + syncClockInChannelDesc + "打卡" ); return ResultDto.success(); } } channelClockInThreadPool.execute(() -> syncClockInRecordFactory.getClockInRecordSyncReqService(param.getClockInChannel()) .syncChannelClockInData(SyncClockInDataArg.fromApiSyncParam(param, currentUser)) ); return ResultDto.success(); }
传入的ApiSyncClockInDataParamDto有一个内部属性SyncTypeEnum,该枚举类包含了所有渠道类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Getter @AllArgsConstructor public enum SyncTypeEnum { DINGDING(1 , "钉钉打卡" , "dingding" ), WEIXIN(2 , "企业微信" , "wechat" ), LARK(3 , "飞书" , "lark" ), TEN_MOONS(4 , "天敏考勤机" , "10moons" ), ZKTECO_CLOUD(5 , "中控云考勤机" , "zktecocloud" ), DINGDING_CHECKIN(ImCheckInChannelEnum.DINGDING_CHECKIN.getChannel(),"钉钉签到" ,"dingding_checkin" ), INTERFACE_SYNC(7 , "接口同步" , "openapi-interface" ), ZKTECO_CLIENT(8 ,"中控终端考勤机" ,"zkteco_client" ), ; @JsonValue private int code; private String desc; private String value;
注意这行代码:
1 2 syncClockInRecordFactory.getClockInRecordSyncReqService(param.getClockInChannel()) .syncChannelClockInData(SyncClockInDataArg.fromApiSyncParam(param, currentUser))
根据param中传入的channel值来获取对应的service(工厂模式的体现),然后调用该service下的syncChannelClockInData方法来处理
这里的数据同步就涉及到了多种同步方式(同步考勤机、定时任务定时拉取、PC端手动导入),下面先介绍定时任务同步方式
1.1 定时任务 设置jobHandler 对应xxl-job的界面为:
其中Cron表达式为: ==0 0/10 * * * ?==
这个 Cron 表达式 0 0/10 * * * ? 表示每隔10分钟执行一次任务。解析如下:
第一个字段(秒):0,表示在每分钟的第 0 秒执行。
第二个字段(分):0/10,表示每隔 10 分钟执行一次。
第三个字段(小时):*,表示每小时都执行。
第四个字段(日):*,表示每月都执行。
第五个字段(月):*,表示每周都执行。
第六个字段(星期):?,表示不指定星期。
第七个字段(年):*,表示每年都执行。
因此,这个表达式表示每隔10分钟执行一次任务,无论是哪一天,哪一个月,哪一年。
再看两个例子:
例子1 ==0 30 1 * * ?==
这个 Cron 表达式 0 30 1 * * ? 表示在每天的凌晨1点30分执行一次任务。解析如下:
第一个字段(秒):0,表示在每分钟的第 0 秒执行。
第二个字段(分):30,表示在每小时的第 30 分钟执行。
第三个字段(小时):1,表示在每天的第 1 小时执行。
第四个字段(日):*,表示每月都执行。
第五个字段(月):*,表示每周都执行。
第六个字段(星期):?,表示不指定星期。
第七个字段(年):*,表示每年都执行。
因此,这个表达式表示在每天凌晨1点30分执行一次任务,无论是哪一天,哪一个月,哪一年。
例子2 ==0 30 5,11,17,23 * * ?==
这个 Cron 表达式 0 30 5,11,17,23 * * ? 表示在每天的凌晨5点30分、11点30分、下午5点30分、晚上11点30分各执行一次任务。解析如下:
第一个字段(秒):0,表示在每分钟的第 0 秒执行。
第二个字段(分):30,表示在每小时的第 30 分钟执行。
第三个字段(小时):5,11,17,23,表示在每天的第 5, 11, 17, 23 小时执行。
第四个字段(日):*,表示每月都执行。
第五个字段(月):*,表示每周都执行。
第六个字段(星期):?,表示不指定星期。
第七个字段(年):*,表示每年都执行。
因此,这个表达式表示在每天的凌晨5点30分、11点30分、下午5点30分、晚上11点30分各执行一次任务。
在这个类中,scheduleTaskRun 方法就是执行定时任务的地方,方法内部通过调用 clockInRecordTaskSyncService 的 syncChannelClockInData 方法,传入构建好的参数对象,执行实际的同步操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 @Service @Slf4j @JobHandler("sync3rdClockInRecordJobHandler") public class Sync3rdClockInRecordJobHandler extends LoopScheduleTaskImplementModule { @Resource private ClockInRecordTaskSyncServiceImpl clockInRecordTaskSyncService; private String AUTO_CALCULATE_APOLLO_KEY = "sync-clock-record-auto-calculate" ; @Override public void scheduleTaskRun (Long entId, Long buId, Map<String, String> otherParam) { log.info("syncClockInRecordTask start....entId : {}, buId : {}, param : {}" , entId, buId, JacksonUtils.toJson(otherParam)); String traceId = UUID.randomUUID().toString().replace("-" , "" ); MDC.put(CommonConstants.TRACE_ID, traceId); SyncClockInDataArg arg = buildDefaultArg(); arg.setEntId(entId); arg.setBuId(buId); SyncClockInRecordTaskParam param = null ; if (MapUtils.isNotEmpty(otherParam)) { try { param = JacksonUtils.parse(JacksonUtils.toJson(otherParam), SyncClockInRecordTaskParam.class); } catch (Exception e) { log.error("syncClockInRecordTask task param fromJson failed, taskParam : {}" , JacksonUtils.toJson(otherParam)); } } Boolean syncAllDay = null ; if (param != null ) { syncAllDay = param.getSyncAllDay(); Long entIdParam = param.getEntId(); Integer channel = param.getChannel(); if (Objects.nonNull(entIdParam) && BooleanUtils.isFalse(entId.equals(entIdParam))) { return ; } if (Objects.nonNull(channel)) { SyncTypeEnum syncTypeEnum = SyncTypeEnum.fromCode(channel); if (syncTypeEnum != null ) { arg.setClockInChannel(syncTypeEnum); } } } if (BooleanUtils.isTrue(syncAllDay)) { DateTime now = DateTime.now().withTime(8 , 0 , 0 , 0 ); Date endDate = now.toDate(); Date startDate = now.minusDays(1 ).withTime(0 , 0 , 0 , 0 ).toDate(); log.info("同步渠道打卡,同步时间:{}~{}" , DateFormatUtils.format(startDate, DatePattern.YMD), DateFormatUtils.format(endDate, DatePattern.YMD)); arg.setStartDate(startDate); arg.setEndDate(endDate); arg.setAutoCalculate(isAutoCalculate()); arg.setWaitPreTaskDone(false ); } clockInRecordTaskSyncService.syncChannelClockInData(arg); }
根据下列代码可以看出:在xxl-job中会定时执行ClockInRecordTaskSyncServiceImpl中的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class ClockInRecordTaskSyncServiceImpl implements ClockInRecordSyncAllChannelReqService { @Resource private HcmAbsenceClockSyncServiceAdapter hcmAbsenceClockSyncServiceAdapter; @Resource private SyncClockInRecordFactory factory; @Override public boolean syncChannelClockInData (SyncClockInDataArg arg) { Assert.notNull(arg, "同步参数信息不能为空" ); Assert.notNull(arg.getEntId(), "租户Id不能为空" ); Assert.notNull(arg.getBuId(), "租户Id不能为空" ); Long entId = arg.getEntId(); Long buId = arg.getBuId(); List<EntCheckInChannelDto> entCheckInChannelDtoList = hcmAbsenceClockSyncServiceAdapter.list3rdCheckInEnt(entId, buId, true ); if (CollectionUtils.isEmpty(entCheckInChannelDtoList)) { log.info("未查询到开启第同步三方打卡的租户 entId: {}" , entId); return true ; } SyncTypeEnum syncTypeEnum = arg.getClockInChannel(); for (EntCheckInChannelDto entCheckInChannel : entCheckInChannelDtoList) { SyncTypeEnum channel = entCheckInChannel.getChannel(); if (Objects.nonNull(syncTypeEnum) && syncTypeEnum != channel) { continue ; } ClockInRecordSyncReqService clockInRecordSyncService = factory.getClockInRecordSyncReqService(channel); SyncClockInDataArg entArg = new SyncClockInDataArg (); BeanUtils.copyProperties(arg, entArg); entArg.setClockInChannel(channel); new ClockInRecordSyncServiceDateWrapper (clockInRecordSyncService).syncChannelClockInData(entArg); } return true ; } }
注意list3rdCheckInEnt()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public List<EntCheckInChannelDto> list3rdCheckInEnt (Long entId, Long buId, boolean loadFromCacheFirst) { String entCheckInChannelRedisKey = buildEntCheckInChannelRedisKey(entId, buId); List<EntCheckInChannelDto> entCheckInChannelDtoList = null ; if (loadFromCacheFirst) { String queryEntCheckInChannelDtoListValueFromRedis = redisTemplate.opsForValue().get(entCheckInChannelRedisKey); if (StringUtils.isNotBlank(queryEntCheckInChannelDtoListValueFromRedis)) { entCheckInChannelDtoList = JacksonUtils.parse(queryEntCheckInChannelDtoListValueFromRedis, new TypeReference <List<EntCheckInChannelDto>>() { }); return entCheckInChannelDtoList; } } List<EntCheckInChannel> entCheckInChannelList = hcmAbsenceClockInService.list3rdCheckInEnt(entId, buId); log.info("list3rdCheckInEnt resp:{}" , JacksonUtils.toJson(entCheckInChannelList)); entCheckInChannelDtoList = EntCheckInChannelDto.entCheckInChannel2Dto(entCheckInChannelList); String queryEntCheckInChannelDtoListValue = JacksonUtils.toJson(entCheckInChannelDtoList); redisTemplate.opsForValue().set(entCheckInChannelRedisKey, queryEntCheckInChannelDtoListValue, 5 , TimeUnit.MINUTES); return entCheckInChannelDtoList; }
这里涉及到一个由EntCheckInChannel到EntCheckInChannelDto的类型转换问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static List<EntCheckInChannelDto> entCheckInChannel2Dto (List<EntCheckInChannel> sources) { List<EntCheckInChannelDto> returnList = Lists.newArrayList(); if (CollectionUtils.isEmpty(sources)) { return returnList; } for (EntCheckInChannel entCheckInChannel : sources) { returnList.add(entCheckInChanel2Dto(entCheckInChannel)); } return returnList; } private static EntCheckInChannelDto entCheckInChanel2Dto (EntCheckInChannel source) {SyncTypeEnum channel = Optional.ofNullable(source.getImCheckInChannel()).map(imCheckInChannelEnum -> SyncTypeEnum.fromCode(imCheckInChannelEnum.getChannel())).orElse(null );return EntCheckInChannelDto.builder().entId(source.getEntId()) .buId(source.getBuId()) .channel(channel) .build(); }
上述代码用到了java8中的Optional(开发中很常用)
其中,Optional.ofNullable(source.getImCheckInChannel())用来优雅处理NullPointerException问题;ImCheckInChannelEnum.map(imCheckInChannelEnum -> SyncTypeEnum.fromCode(imCheckInChannelEnum.getChannel())) 在映射过程中,通过调用 imCheckInChannelEnum.getChannel() 方法获取打卡渠道的代码,然后使用 SyncTypeEnum.fromCode() 方法将代码转换为相应的 SyncTypeEnum 枚举值。如果转换成功,返回转换后的枚举值; ImCheckInChannelEnum和 SyncTypeEnum两个枚举类对应的value不一致,需要进行同步 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public enum SyncTypeEnum { DINGDING(1 , "钉钉打卡" , "dingding" ), WEIXIN(2 , "企业微信" , "wechat" ), LARK(3 , "飞书" , "lark" ), TEN_MOONS(4 , "天敏考勤机" , "10moons" ), ZKTECO_CLOUD(5 , "中控云考勤机" , "zktecocloud" ), DINGDING_CHECKIN(ImCheckInChannelEnum.DINGDING_CHECKIN.getChannel(),"钉钉签到" ,"dingding_checkin" ), INTERFACE_SYNC(7 , "接口同步" , "openapi-interface" ), ZKTECO_CLIENT(8 ,"中控终端考勤机" ,"zkteco_client" ), ; } --------------- public enum ImCheckInChannelEnum { DINGDING_CHECKIN(ImTypeEnum.DINGDING.getCode(), "钉钉签到" , 6 ), DINGDING(ImTypeEnum.DINGDING.getCode(), "钉钉打卡" , 1 ), WEIXIN(ImTypeEnum.WEIXIN.getCode(), "企业微信" , 2 ), LARK(ImTypeEnum.LARK.getCode(), "飞书打卡" , 3 ); }
然后回到核心同步的逻辑处:new ClockInRecordSyncServiceDateWrapper(clockInRecordSyncService).syncChannelClockInData(entArg); 这里需要注意 实际调用的方法是AbstractChannelClockInRecordSyncService中的syncChannelClockInData方法:
这是为什么❓❓
该抽象类中的syncChannelClockInData方法实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 @Transactional(rollbackFor = Exception.class) @Override public boolean syncChannelClockInData (SyncClockInDataArg arg) {log.info("开始执行同步打卡数据任务,请求参数:{}" , JacksonUtils.toJson(arg)); arg.check(); Long entId = arg.getEntId();Long buId = arg.getBuId();SyncTypeEnum syncTypeEnum = arg.getClockInChannel();List<Long> blackEntList = getBlackEntList(); if (blackEntList.contains(entId)) { log.warn("企业不允许进行打卡数据同步, entId:" + entId + ", blackEntList:" + JacksonUtils.toJson(blackEntList)); return true ; } List<SyncTypeEnum> blackChannelList = getBlackChannelList(); if (blackChannelList.contains(syncTypeEnum)) { log.warn("不允许当前渠道的打卡数据同步, entId:" + entId + ", channel:" + syncTypeEnum + ", blackChannelList:" + JacksonUtils.toJson(blackChannelList)); return true ; } Date syncStartDate = arg.getStartDate();Date syncEndDate = DateUtil.getMaxTimeOfDay(arg.getEndDate());EntDto entDto = EntDto.builder().entId(entId).buId(buId).build();List<EmployeeInfoDto> employeeInfoDtoList = hrJobInfoAdapter.getEmployeesByEnt(entDto, true ); List<Long> employeeIds = SyncEmployeeFilter.filterValidEmployee(entId,buId,employeeInfoDtoList, syncStartDate); if (CollectionUtils.isEmpty(employeeIds)) { log.info("未查询到 ent:{}, buId:{} 员工信息,{}打卡记录同步结束." , entId, buId, getChannelDesc()); return true ; } if (BooleanUtils.isTrue(arg.getWaitPreTaskDone()) && !preTaskDone(entId, buId, arg.getClockInChannel(), employeeIds)) { return false ; } List<DateScope> dateScopes = DateUtil.partition(syncStartDate, syncEndDate, getMaxSyncDay()); log.info("时间拆分后为:{}" , JacksonUtils.toJson(dateScopes)); String transId = arg.buildTransId();syncLogService.save(buildDingTalkSyncLog(arg, new Date (), transId)); for (DateScope dateScope : dateScopes) { SyncChannelClockRecordReqDto syncChannelClockRecordReqDto = buildSyncChannelClockRecordReqDto(entId, buId, employeeIds, transId, dateScope); log.info("asyncPull3rdCheckInRecord ,syncChannelClockRecordReqDto:{}" , syncChannelClockRecordReqDto); hcmAbsenceClockSyncServiceAdapter.asyncPull3rdCheckInRecord(syncChannelClockRecordReqDto); } return true ;}
真正执行打卡数据同步的逻辑在 syncChannelClockInData() 方法中,通过调用适配器对象的方法进行异步打卡记录同步:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class HcmAbsenceClockSyncServiceAdapterImpl implements HcmAbsenceClockSyncServiceAdapter { @Override public void asyncPull3rdCheckInRecord (SyncChannelClockRecordReqDto syncChannelClockRecordReqDto) { DateScope syncDateScope = syncChannelClockRecordReqDto.getDateScope(); SyncTypeEnum syncChannelType = syncChannelClockRecordReqDto.getChannel(); Long entId = syncChannelClockRecordReqDto.getEntId(); Long buId = syncChannelClockRecordReqDto.getBuId(); PullChannelCheckInRecordReq pullChannelCheckInRecordReq = PullChannelCheckInRecordReq.builder() .entId(entId) .buId(buId) .startDate(syncDateScope.getStartDate()) .endDate(syncDateScope.getEndDate()) .employeeIds(syncChannelClockRecordReqDto.getEmployeeIds()) .checkInChannel(ImCheckInChannelEnum.getEnumByChannelCode(syncChannelType.getCode())) .transId(syncChannelClockRecordReqDto.getTransId()) .build(); try { log.info("asyncPull3rdCheckInRecord req:{}" , JacksonUtils.toJson(pullChannelCheckInRecordReq)); BaseResult result = hcmAbsenceClockInService.asyncPull3rdCheckInRecord(pullChannelCheckInRecordReq); if (!result.isSuccess()) { log.warn("asyncPull3rdCheckInRecord failed, result:{}" , JacksonUtils.toJson(result)); } } catch (Exception e) { log.error("同步" + syncChannelType.getDesc() + "打卡数据异常,ent:{}, buId:{}." , entId, buId, e); } } }
==只关注核心逻辑==:
BaseResult result = hcmAbsenceClockInService.asyncPull3rdCheckInRecord(pullChannelCheckInRecordReq);
1、该方法首先会调用 hcm-mobile-client 模块 下的pull3rdCheckInRecord方法:
2、然后通过openFeign远程调用 ==hcm-mobile==模块下的 :
其入口url在 hcm——mobile下:
/client/api/mobile/absence/pull3rdCheckInRecord
3、 hcm-mobile下对应的controller及service代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @PostMapping(value = "/absence/pull3rdCheckInRecord", produces = "application/json") BaseResult pull3rdCheckInRecord (@RequestBody PullChannelCheckInRecordReq pullChannelCheckInRecordReq,CurrentUserDto currentUserDto) { return absenceService.pull3rdCheckInRecord(pullChannelCheckInRecordReq,currentUserDto); } public BaseResult pull3rdCheckInRecord (PullChannelCheckInRecordReq req, CurrentUserDto currentUserDto) { ImCheckInChannelEnum imCheckInChannel = req.getCheckInChannel(); if (Objects.isNull(imCheckInChannel)) { return BaseResult.buildResult(ErrorCodeEnum.SYS_INVALID_PARAMS); } HcmImEntService<?> hcmImEntService = HcmMobileEntServiceFactory.createHcmImEntService(imCheckInChannel.getImType()); List<EntCheckInChannel> absenceModes = hcmImEntService.getAbsenceModeNew(req.getEntId(), req.getBuId()); log.info("search entId -{} buId - {} ent check in channel :{}" , req.getEntId(), req.getBuId(), JsonUtils.toJsonString(absenceModes)); if (CollectionUtils.isEmpty(absenceModes)) { log.info("打卡数据同步开关未开启:ent:{},channel:{}" , req.getEntId(), JacksonUtils.toJson(req.getCheckInChannel())); return BaseResult.buildResult(ErrorCodeEnum.PUNCH_DATA_SWITCH_CLOSE); } boolean switchFlag = false ; for (EntCheckInChannel absenceMode : absenceModes) { if (absenceMode.getImCheckInChannel().equals(imCheckInChannel)) { switchFlag = true ; } } if (!switchFlag) { log.info("打卡数据同步开关未开启:ent:{},channel:{}" , req.getEntId(), JacksonUtils.toJson(req.getCheckInChannel())); return BaseResult.buildResult(ErrorCodeEnum.PUNCH_DATA_SWITCH_CLOSE); } HcmMobileAbsenceService hcmIntegrationService = HcmMobileAbsenceServiceFactory.createHcmMobileAbsenceService(imCheckInChannel); hcmIntegrationService.pullAbsenceData(req, currentUserDto); return BaseResult.buildResult(ErrorCodeEnum.SUCCESS); }
注意这里根据不同的打卡渠道,需要查询==对应租户是否开启了对应渠道的打卡数据同步方式 :exclamation::exclamation:==
以钉钉、飞书为例:
1.2 主动Pull 拉取第三方渠道 hcmIntegrationService.pullAbsenceData(req, currentUserDto);
拉取飞书打卡 有几点注意事项:
然后我们再来看逻辑代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public void pullAbsenceData (PullChannelCheckInRecordReq req, CurrentUserDto userDto) { Long entId = req.getEntId(); Long buId = req.getBuId(); HcmLarkEnt hcmLarkEnt = hcmLarkEntDao.findByEntId(entId, buId); String corpId = hcmLarkEnt.getCorpId(); List<Long> employeeIds = req.getEmployeeIds(); List<List<Long>> lists = ListUtils.partition(employeeIds, ImIntegrationConstants.LARK_MAX_COUNT_PULL); for (List<Long> list : lists) { PUNCH_DATA_SYNC_EXECUTOR.execute(() -> { asyncPullPunchData(list, req, corpId); }); } }
进入到 **asyncPullPunchData **方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public void asyncPullPunchData (List<Long> list, PullChannelCheckInRecordReq req, String corpId) { Long entId= req.getEntId(); accessLimitService.larkAbsenceAcquireByEnt(req.getEntId()); List<HcmLarkUser> hcmLarkUsers = hcmLarkUserDao.findByEmployeeIds(req.getEntId(), req.getBuId(), corpId, list); Map<Long, String> employeeIdUserIdMap = hcmLarkUsers.parallelStream() .filter(hcmLarkUser -> DataStatusEnum.ENABLE.getStatus() == hcmLarkUser.getBindStatus()) .collect(Collectors.toMap(HcmLarkUser::getEmployeeId, HcmLarkUser::getUserid, (v1, v2) -> v2)); List<ChannelCheckInDataRes> resList = new ArrayList <>(); List<String> userIdList = new ArrayList <>(employeeIdUserIdMap.values()); List<LarkAttendanceUserFlowRespVO> records = new ArrayList <>(); if (!employeeIdUserIdMap.isEmpty()) { records = getPunchRecord(userIdList, req, corpId); } Map<String, List<LarkAttendanceUserFlowRespVO>> larkClockRecordMap = records.stream().collect(Collectors.groupingBy(item -> item.getUserId())); if (!larkClockRecordMap.isEmpty()) { log.info("查询到的飞书打卡数据结果集 :{}" , JsonUtils.toJsonString(larkClockRecordMap)); } for (Long employeeId : list) { ChannelCheckInDataRes channelCheckInDataRes = new ChannelCheckInDataRes (); channelCheckInDataRes.setChannel(ImCheckInChannelEnum.LARK); channelCheckInDataRes.setBuId(req.getBuId()); channelCheckInDataRes.setEntId(req.getEntId()); channelCheckInDataRes.setEmployeeId(employeeId); channelCheckInDataRes.setTransId(req.getTransId()); String userId = employeeIdUserIdMap.get(employeeId); if (!StringUtils.isEmpty(userId) && larkClockRecordMap.containsKey(userId)) { for (LarkAttendanceUserFlowRespVO larkClockRecord : larkClockRecordMap.get(userId)) { ChannelCheckInDataRes channelCheckInDataResSuccess = new ChannelCheckInDataRes (); BeanUtils.copyProperties(channelCheckInDataRes, channelCheckInDataResSuccess); channelCheckInDataResSuccess.setOutsideClock(larkClockRecord.getIsField()); channelCheckInDataResSuccess.setOutsideRemark(larkClockRecord.getComment()); channelCheckInDataResSuccess.setCheckInSource(Integer.toString(larkClockRecord.getType())); channelCheckInDataResSuccess.setCheckInTime(Long.valueOf(larkClockRecord.getCheckTime())); channelCheckInDataResSuccess.setDeviceId(larkClockRecord.getDeviceId()); channelCheckInDataResSuccess.setLocationDetail(larkClockRecord.getLocationName()); channelCheckInDataResSuccess.setOriginData(JacksonUtils.toJson(larkClockRecord)); channelCheckInDataResSuccess.setRecordId(larkClockRecord.getRecordId()); channelCheckInDataResSuccess.setVerify(Objects.toString(larkClockRecord.getType(), null )); if (CollectionUtils.isNotEmpty(larkClockRecord.getPhotoUrls())) { channelCheckInDataResSuccess.setImg(larkClockRecord.getPhotoUrls().get(0 )); } resList.add(channelCheckInDataResSuccess); } continue ; } resList.add(channelCheckInDataRes); } absenceMsgProducer.pushMsg(resList,entId); }
流程如下:
从请求参数 req 中获取企业ID
对飞书打卡数据拉取的访问限制:
使用企业ID构建了一个用于存储在 Redis 中的键
使用 redisLimitTemplate 初始化一个令牌桶限流器,每秒生成 40 - LIMIT_BUFFER 个令牌,即每秒填充 40 - LIMIT_BUFFER 个令牌到令牌桶中 ,这里使用了RRateLimiter分布式限流器 ,相关文章链接如下:
查询这些飞书用户对应在hcm中的租户信息 ,构建员工ID到飞书用户ID的映射
==获取飞书打卡记录: getPunchRecord()方法==
按用户ID分组打卡记录,遍历员工ID列表,构建打卡数据结果,构建打卡数据结果列表
构建好的打卡数据结果通过kafka发送异步消息 消费者批量消费
针对其中的第四步 ,获取飞书打卡记录这里,方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public List<LarkAttendanceUserFlowRespVO> getPunchRecord (List<String> list, PullChannelCheckInRecordReq req, String corpId) { Date startDate = req.getStartDate(); Date endDate = req.getEndDate(); GetLarkAttendanceUserFlowBatchReqVO getLarkAttendanceUserFlowBatchReqVO = GetLarkAttendanceUserFlowBatchReqVO.builder() .checkTimeFrom(Long.toString(startDate.getTime() / 1000 )) .checkTimeTo(Long.toString(endDate.getTime() / 1000 )) .employeeType(ImIntegrationConstants.LARK_EMPLOYEE_ID_TYPE) .includeTerminatedUser(true ) .userIds(list) .build(); getLarkAttendanceUserFlowBatchReqVO.setAppType(ImIntegrationConstants.LARK_SELF); getLarkAttendanceUserFlowBatchReqVO.setCorpId(corpId); getLarkAttendanceUserFlowBatchReqVO.setBus(ImIntegrationConstants.REQUEST_BUS); RespEntity<LarkAttendanceUserFlowBatchRespVO> larkAttendanceUserFlowsBatch = larkAttendanceApi.getLarkAttendanceUserFlowsBatch(getLarkAttendanceUserFlowBatchReqVO); if (null == larkAttendanceUserFlowsBatch || null == larkAttendanceUserFlowsBatch.getData()) { log.info("查询飞书打卡记录接口获取失败 :{}" , JsonUtils.toJsonString(getLarkAttendanceUserFlowBatchReqVO)); return Collections.EMPTY_LIST; } LarkAttendanceUserFlowBatchRespVO larkAttendanceUserFlowBatchRespVO = larkAttendanceUserFlowsBatch.getData(); List<LarkAttendanceUserFlowRespVO> userFlowList = larkAttendanceUserFlowBatchRespVO.getUserFlowList(); if (RespCode.SUCCESS.getCode() != larkAttendanceUserFlowsBatch.getCode()) { log.info("查询飞书打卡记录接口获取失败 exception :{} response:{}" , JsonUtils.toJsonString(getLarkAttendanceUserFlowBatchReqVO) , JsonUtils.toJsonString(larkAttendanceUserFlowsBatch)); return Collections.EMPTY_LIST; } return userFlowList == null ? Collections.EMPTY_LIST : userFlowList; }
通过封装好的LarkAttendanceApi来批量查询用户的飞书打卡记录:
该接口位于moka-lark下: LarkAttendanceInnerController.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @RestController @RequestMapping("/api/inner/moka-lark/attendance") public class LarkAttendanceInnerController implements LarkAttendanceApi { @Autowired private LarkAttendanceService larkAttendanceService; @Override @ApiOperation("批量查询用户飞书打卡记录") @PostMapping(value = "/getLarkAttendanceUserFlowsBatch") public RespEntity<LarkAttendanceUserFlowBatchRespVO> getLarkAttendanceUserFlowsBatch (@RequestBody GetLarkAttendanceUserFlowBatchReqVO reqVO) { try { LarkAttendanceUserFlowBatchRespVO respVO = larkAttendanceService.getLarkAttendanceUserFlowBatch(reqVO); return RespEntity.respSuccess(respVO); } catch (Exception e) { if (e instanceof ServiceException) { return RespEntity.resp(((ServiceException) e).getCode(), e.getMessage(), null ); } return RespEntity.respFail("LarkAttendanceInnerController getLarkAttendanceUserFlowsBatch error: " + e.getMessage()); } } }
因为是ATS的项目,具体就不细看了,只看最终调用代码,实际上是通过Unirest发送http请求给飞书开放平台来请求打卡数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public String getUserFlowBatch (String tenantAccessToken, GetLarkAttendanceUserFlowBatchReqVO vo) throws UnirestException { String url = LarkConstants.LARK_OPEN_API_URL + LarkConstants.LARK_V1_ATTENDANCE_USER_FLOWS_QUERY_URL; GetLarkUserFlowBatchRequestParam requestParam = GetLarkUserFlowBatchRequestParam.builder() .employee_type(vo.getEmployeeType()) .include_terminated_user(vo.getIncludeTerminatedUser()) .build(); GetLarkUserFlowBatchRequestBodyParam requestBodyParam = GetLarkUserFlowBatchRequestBodyParam.builder() .user_ids(vo.getUserIds()) .check_time_from(vo.getCheckTimeFrom()) .check_time_to(vo.getCheckTimeTo()) .build(); try { HttpResponse<JsonNode> response = Unirest .post(url) .header("Content-Type" , MediaType.APPLICATION_JSON_VALUE) .header("Accept" , MediaType.APPLICATION_JSON_VALUE) .header("Authorization" , tenantAccessToken) .queryString(gson.fromJson(gson.toJson(requestParam), Map.class)) .body(gson.toJson(requestBodyParam)) .asJson(); LarkResponse larkResponse = JSONObject.parseObject(response.getBody().toString(), LarkResponse.class); if (response.getStatus() != HttpStatusEnum.SUCCESS.value() || larkResponse.getCode() != OK_CODE) { throw new ServiceException (larkResponse.getCode(), larkResponse.getMsg() + StrUtil.nullToEmpty(larkResponse.getError())); } return gson.toJson(larkResponse.getData()); } catch (Exception e) { log.error("LarkAttendanceDaoImpl getUserFlowsBatch error! tenantAccessToken=[{}],error=[{}]" , tenantAccessToken, e); throw e; } }
什么是Unirest?
拉取企业微信打卡 拉取企微打卡数据的逻辑和拉取飞书类似,这里只关注不同点 :grey_exclamation: :grey_exclamation:
先看看入口url:
拉取企微数据的核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 public void asyncPullPunchData (List<Long> list, long entId,long buId, Date startDate, Date endDate,String transId , String corpId, String punchSecret) { accessLimitService.wechatAbsenceAcquireByEnt(entId); List<HcmWxinUser> hcmWxinUsers = hcmWxinUserDao.findByEmployeeIds(entId, buId, corpId, list); List<HcmWxinUser> noOriUserIdList = hcmWxinUsers.stream().filter(hcmWxinUser -> StringUtils.isBlank(hcmWxinUser.getOriginalUserId())).collect(Collectors.toList()); Map<Long, String> employeeIdUserIdMap = hcmWxinUsers.stream().filter(hcmWxinUser -> StringUtils.isNotBlank(hcmWxinUser.getOriginalUserId())) .collect(Collectors.toMap(HcmWxinUser::getEmployeeId, HcmWxinUser::getOriginalUserId, (v1, v2) -> v2)); if (CollectionUtils.isNotEmpty(noOriUserIdList)){ List<Long> employeeIdList = noOriUserIdList.stream().map(HcmWxinUser::getEmployeeId).collect(Collectors.toList()); HashMap<Long, String> employeeTelephoneByEmployeeId = imHandleManager.getEmployeeTelephoneByEmployeeId(entId, buId, employeeIdList, true ); for (HcmWxinUser hcmWxinUser : noOriUserIdList) { Long employeeId = hcmWxinUser.getEmployeeId(); String telephone = employeeTelephoneByEmployeeId.get(employeeId); if (StringUtils.isBlank(telephone)) { log.warn("该员工查到的手机号不合法,employeeId: {}, telephone: {}" , employeeId, telephone); continue ; } GetUserIdByPhoneReqDTO params = GetUserIdByPhoneReqDTO.builder().corpId(hcmWxinUser.getCorpid()).corpSecret(punchSecret).phone(telephone).build(); String workWechatUserId = "" ; try { String redisUserid = redisClient.getValue(PHONE_USERID_REDIS_PRE+telephone); if (StringUtils.isNotBlank(redisUserid)){ log.info("redisUserid is :{}" ,redisUserid); continue ; } AtsRespEntity<GetUserIdByPhoneRespDTO> workWechatUserIdByPhone = iWorkWechatAddressBookUserInnerApi.getWorkwechatUserIdByPhone(params); log.info("通过手机号换取userId结果:{}" , JacksonUtils.toJson(workWechatUserIdByPhone)); if (workWechatUserIdByPhone.isSuccess()){ GetUserIdByPhoneRespDTO data = workWechatUserIdByPhone.getData(); workWechatUserId = data.getWorkwechatUserId(); hcmWxinUser.setOriginalUserId(workWechatUserId); employeeIdUserIdMap.put(employeeId, workWechatUserId); hcmWxinUserDaoAdapter.buildUserId(hcmWxinUser); }else { try { redisClient.setValue(PHONE_USERID_REDIS_PRE + telephone, telephone, 12 , TimeUnit.HOURS); log.info("query by phone:{}" , telephone); } catch (Exception e) { log.error("redis function error. userid:{} , phone:{}" , workWechatUserId, telephone,e); } } } catch (Exception e) { log.error("使用punchSecret获取员工userId失败:入参{}:租户:{}" ,JacksonUtils.toJson(params),entId,e); } } log.info("重建原始userId结果:{}" ,JacksonUtils.toJson(noOriUserIdList)); } List<ChannelCheckInDataRes> resList = new ArrayList <>(); List<String> userIdList = new ArrayList <>(employeeIdUserIdMap.values()); List<GetWorkwechatCardRespDTO> punchRecord = getPunchRecord(userIdList, startDate, endDate, corpId, punchSecret); Map<String, List<GetWorkwechatCardRespDTO>> punchRecordMap = punchRecord.stream().collect(Collectors.groupingBy(GetWorkwechatCardRespDTO::getUserId)); if (!punchRecordMap.isEmpty()){ log.info("查询到的企业微信打卡数据:{}" , JacksonUtils.toJson(punchRecordMap)); } for (Long employeeId : list) { ChannelCheckInDataRes channelCheckInDataRes = new ChannelCheckInDataRes (); channelCheckInDataRes.setChannel(ImCheckInChannelEnum.WEIXIN); channelCheckInDataRes.setBuId(buId); channelCheckInDataRes.setEntId(entId); channelCheckInDataRes.setEmployeeId(employeeId); channelCheckInDataRes.setTransId(transId); String userId = employeeIdUserIdMap.get(employeeId); if (!StringUtils.isEmpty(userId) && punchRecordMap.containsKey(userId)) { for (GetWorkwechatCardRespDTO datum : punchRecordMap.get(userId)) { ChannelCheckInDataRes channelCheckInDataResSuccess = new ChannelCheckInDataRes (); BeanUtils.copyProperties(channelCheckInDataRes, channelCheckInDataResSuccess); channelCheckInDataResSuccess.setWechatException(datum.getExceptionType()); channelCheckInDataResSuccess.setCheckInSource(datum.getCheckinSource()); channelCheckInDataResSuccess.setCheckInTime(datum.getCheckinTime()); channelCheckInDataResSuccess.setDeviceId(datum.getDeviceId()); channelCheckInDataResSuccess.setLocationDetail(datum.getLocationDetail()); channelCheckInDataResSuccess.setOutsideClock(datum.getCheckinType()); channelCheckInDataResSuccess.setOutsideRemark(datum.getNotes()); channelCheckInDataResSuccess.setOriginData(JacksonUtils.toJson(datum)); resList.add(channelCheckInDataResSuccess); } continue ; } resList.add(channelCheckInDataRes); } absenceMsgProducer.pushMsg(resList,entId); }
限流控制:
调用 accessLimitService.wechatAbsenceAcquireByEnt(entId) 方法,进行企业微信外部接口调用的限流控制。
获取企业微信用户信息:
通过企业ID(entId)、部门ID(buId)、企业微信CorpId(corpId)、员工ID列表(list)等参数,从数据库中获取企业微信用户信息列表 hcmWxinUsers。
获取无原始用户ID的用户列表 noOriUserIdList:
从企业微信用户信息列表中过滤出没有原始用户ID(OriginalUserId)的用户列表 noOriUserIdList
获取员工ID与企业微信用户ID的映射关系 employeeIdUserIdMap:
通过 Java 8 的 Stream API,将具有原始用户ID的用户信息映射为员工ID与企业微信用户ID的关系,存储在 employeeIdUserIdMap 中。
处理无原始用户ID的用户列表:
对于没有原始用户ID的用户,尝试通过手机号码从企业微信获取用户ID。
如果手机号在Redis中有记录,则跳过;否则,通过企业微信接口查询手机号对应的用户ID,并更新用户信息。
构建推送打卡数据的结果列表 resList:
通过用户ID列表调用 getPunchRecord 方法,获取企业微信用户的打卡记录。
根据打卡记录构建推送打卡数据的结果列表 resList。
推送打卡数据:
调用 absenceMsgProducer.pushMsg(resList, entId) 方法,将打卡数据异步推送到消息队列。
1、调用外部api限流频率差异
令牌生成的速率为 10 令牌每秒(即每秒最多允许 10 次请求),缓冲区大小为 LIMIT_BUFFER。LIMIT_BUFFER 的值应该是一个小于令牌生成速率的数值,用于确保即使在速率正好用尽时,请求也能够通过。在这里,速率是每秒 10 次,LIMIT_BUFFER 为 1,所以实际上是每秒最多允许 11 次请求:
1 2 3 4 5 6 7 8 9 10 public void wechatAbsenceAcquireByEnt (Long entId) { String key = "mobile:limiter:wXin:absence:" + entId; log.info("wechatAbsenceAcquireByEnt:{}" , key); redisLimitTemplate.initRateLimiter(key, 10 - LIMIT_BUFFER, 1 , RateIntervalUnit.SECONDS); boolean acquire = redisLimitTemplate.tryAcquire(key, LIMITER_WAIT_TIME, TimeUnit.SECONDS); if (!acquire) { log.info("请求被限流控制,entId:{}" ,entId); throw new CustomException ("请求被限流控制,请稍后重试" ); } }
企业微信开发者中心规定了接口的访问频率:访问频率限制
2、类似飞书、同样有一张表记录企业微信用户和 hcm 租户之间的对应关系:
同时,表``hcm_wxin_user`记录了所有企业微信用户隶属于的hcm租户信息:
3、针对hcm-wxin-user表中的空用户问题处理(处理缓存击穿)
先来理解一下什么是 original_user_id ?
1、数据库中有一张表 hcm_wxin_user,该表记录了所有hcm用户在moka中的id,同时记录了这些用户在企业微信中的原始id
2、在对企业微信用户列表 hcmWxinUsers 进行处理时,过滤出那些 OriginalUserId 不为空的用户,然后将符合条件的用户映射为一个 Map<Long, String> 类型的集合,其中键为用户的员工ID(getEmployeeId()方法返回的值),值为用户的企业微信用户ID(getOriginalUserId()方法返回的值)
3、最终调用企微api批量查询这些员工的打卡记录,传入参数则为OriginalUserId的List
在处理那些noOriginUserId的用户时:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 List<HcmWxinUser> noOriUserIdList = hcmWxinUsers.stream().filter(hcmWxinUser -> StringUtils.isBlank(hcmWxinUser.getOriginalUserId())).collect(Collectors.toList()); if (CollectionUtils.isNotEmpty(noOriUserIdList)){ List<Long> employeeIdList = noOriUserIdList.stream().map(HcmWxinUser::getEmployeeId).collect(Collectors.toList()); HashMap<Long, String> employeeTelephoneByEmployeeId = imHandleManager.getEmployeeTelephoneByEmployeeId(entId, buId, employeeIdList, true ); for (HcmWxinUser hcmWxinUser : noOriUserIdList) { Long employeeId = hcmWxinUser.getEmployeeId(); String telephone = employeeTelephoneByEmployeeId.get(employeeId); if (StringUtils.isBlank(telephone)) { log.warn("该员工查到的手机号不合法,employeeId: {}, telephone: {}" , employeeId, telephone); continue ; } GetUserIdByPhoneReqDTO params = GetUserIdByPhoneReqDTO.builder().corpId(hcmWxinUser.getCorpid()).corpSecret(punchSecret).phone(telephone).build(); String workWechatUserId = "" ; try { String redisUserid = redisClient.getValue(PHONE_USERID_REDIS_PRE+telephone); if (StringUtils.isNotBlank(redisUserid)){ log.info("redisUserid is :{}" ,redisUserid); continue ; } AtsRespEntity<GetUserIdByPhoneRespDTO> workWechatUserIdByPhone = iWorkWechatAddressBookUserInnerApi.getWorkwechatUserIdByPhone(params); log.info("通过手机号换取userId结果:{}" , JacksonUtils.toJson(workWechatUserIdByPhone)); if (workWechatUserIdByPhone.isSuccess()){ GetUserIdByPhoneRespDTO data = workWechatUserIdByPhone.getData(); workWechatUserId = data.getWorkwechatUserId(); hcmWxinUser.setOriginalUserId(workWechatUserId); employeeIdUserIdMap.put(employeeId, workWechatUserId); hcmWxinUserDaoAdapter.buildUserId(hcmWxinUser); }else { try { redisClient.setValue(PHONE_USERID_REDIS_PRE + telephone, telephone, 12 , TimeUnit.HOURS); log.info("query by phone:{}" , telephone); } catch (Exception e) { log.error("redis function error. userid:{} , phone:{}" , workWechatUserId, telephone,e); } } } catch (Exception e) { log.error("使用punchSecret获取员工userId失败:入参{}:租户:{}" ,JacksonUtils.toJson(params),entId,e); } } log.info("重建原始userId结果:{}" ,JacksonUtils.toJson(noOriUserIdList)); }
在通过该员工手机号来获取它在企业微信中的对应id时,需要调用以下接口:
如果通过该员工的手机号成功获取到其在企微中的userId
将其设置为用户的原始用户ID(OriginalUserId)。
更新 employeeIdUserIdMap 中的映射关系,表示该用户已经有了原始用户ID。
调用 hcmWxinUserDaoAdapter.buildUserId(hcmWxinUser) 更新数据库中的用户信息
如果通过手机号查询用户ID失败,设置锁的过期时间为12小时,即在接下来的12小时内,对于相同的手机号不再进行用户ID的查询
即在发生失败时,通过 redisClient 设置一个锁(实际上是在 Redis 中设置一个键值对),以避免在接下来的12小时内对相同手机号进行用户ID的重复查询。这个锁的键是由手机号构建的,而值则被设置为手机号本身:redisClient.setValue(PHONE_USERID_REDIS_PRE + telephone, telephone, 12, TimeUnit.HOURS);
4、外部调用企业微信接口批量查询打卡记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public List<GetWorkwechatCardRespDTO> getPunchRecord (List<String> list, Date startDate, Date endDate, String corpId, String punchSecret) { if (CollectionUtils.isEmpty(list)){ return new ArrayList <>(); } GetWorkwechatCardReqDTO params = new GetWorkwechatCardReqDTO (); params.setCorpId(corpId); params.setStarttime(startDate.getTime() / 1000 ); params.setEndtime(endDate.getTime() / 1000 ); params.setUseridlist(list); params.setOpencheckindatatype(3 ); params.setCorpSecret(punchSecret); params.setSuiteType(suite); log.info("查询企业微信打卡记录入参:{}" , JacksonUtils.toJson(params)); AtsRespEntity<List<GetWorkwechatCardRespDTO>> resp = new AtsRespEntity <>(); try { resp = workWechatUserInnerApi.getCard(params); } catch (Exception exception) { log.error("企业微信获取打卡数据异常 exception :{}" ,exception); } if (resp.isSuccess()) { return resp.getData(); } return new ArrayList <>(); }
该接口位置在moka-workwechat下,只看核心代码,实际上还是发送http请求来获取数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 public List<GetWorkwechatCardRespDTO> getCard (GetWorkwechatCardReqDTO dto) throws Exception { String accessToken = getCardToken(dto.getCorpId(), dto.getCorpSecret()); if (StringUtils.isBlank(accessToken)) { log.info("get accessToken error. corpId:{},corpSecret:{}" , dto.getCorpId(), dto.getCorpSecret()); throw new Exception ("get accessToken error" ); } if (ObjectUtil.isEmpty(dto.getUseridlist()) || 0 == dto.getUseridlist().size()) { return new ArrayList <>(); } Map<String, Object> params = new HashMap <>(); params.put("opencheckindatatype" , CHECKIN_DATA_TYPE); params.put("useridlist" , dto.getUseridlist()); params.put("starttime" , dto.getStarttime()); params.put("endtime" , dto.getEndtime()); String result = HttpClientUtil.postJson(CHECKIN_DATA_URL + accessToken, JSONUtil.toJsonStr(params), null ); log.info("get checkin data result:{}" , result); JSON json = JSONUtil.parse(result); Integer errCode = (Integer) JSONUtil.getByPath(json, "errcode" ); if (errCode != 0 ) { throw new Exception (JSONUtil.getByPath(json, "errmsg" ) + "" ); } JSONArray dataList = (JSONArray) JSONUtil.getByPath(json, "checkindata" ); Iterator<Object> iterator = dataList.stream().iterator(); List<GetWorkwechatCardRespDTO> list = new ArrayList <>(dataList.size()); while (iterator.hasNext()) { JSONObject object = (JSONObject) iterator.next(); GetWorkwechatCardRespDTO respDTO = new GetWorkwechatCardRespDTO (); respDTO.setUserId(object.getStr("userid" )); respDTO.setCheckinTime(object.getLong("checkin_time" )); respDTO.setDeviceId(object.getStr("deviceid" )); respDTO.setLocationDetail(object.getStr("location_detail" )); respDTO.setCheckinSource("企业微信" ); respDTO.setNotes(object.getStr("notes" )); if ("外出打卡" .equals(object.getStr("checkin_type" ))) { respDTO.setCheckinType(true ); } else { respDTO.setCheckinType(false ); } String wifiName = object.getStr("wifiname" ); if (StringUtils.isNotBlank(wifiName)) { respDTO.setCheckinMethod(1 ); } else { Long lat = object.getLong("lat" ); Long lng = object.getLong("lng" ); if (Objects.nonNull(lat) && Objects.nonNull(lng)) { respDTO.setCheckinMethod(0 ); } } respDTO.setExceptionType(object.getStr("exception_type" )); respDTO.setWifiMac(object.getStr("wifimac" )); respDTO.setMediaIds(object.get("mediaids" , List.class)); respDTO.setGroupName(object.getStr("groupname" )); respDTO.setGroupId(object.getInt("groupid" )); respDTO.setScheduleId(object.getInt("schedule_id" )); respDTO.setTimelineId(object.getInt("timeline_id" )); list.add(respDTO); } return list; } public static String postJson (String url, String json, Map<String, String> headers) { CloseableHttpClient httpClient = HttpClientBuilder.create().build(); HttpPost post = new HttpPost (url); post.setHeader("Content-Type" , "application/json;charset=UTF-8" ); if (Objects.nonNull(headers)) { for (Map.Entry<String, String> entry : headers.entrySet()) { String mapKey = entry.getKey(); String mapValue = entry.getValue(); post.setHeader(mapKey, mapValue); } } String response = null ; try { StringEntity s = new StringEntity (json, "utf-8" ); post.setEntity(s); log.info("HttpUtilsConsumer.doPostJson请求入参post=" + JSON.toJSONString(post)); HttpResponse res = httpClient.execute(post); if (HttpStatus.SC_OK <= res.getStatusLine().getStatusCode() && res.getStatusLine().getStatusCode() < HttpStatus.SC_MULTIPLE_CHOICES) { String result = EntityUtils.toString(res.getEntity()); response = result; } else { log.info("postJson httpstatus error {} {}" , res.getStatusLine().getStatusCode(), EntityUtils.toString(res.getEntity())); throw new Exception (); } } catch (Exception e) { log.error("http接口调用失败" + ",url=" + url + ",param=" + json, e); } return response; }
拉取钉钉打卡 钉钉同理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void dingAbsenceAcquireByEnt (Long entId) { String key = "mobile:limiter:ding:absence:" + entId; log.info("dingAbsenceAcquireByEnt:{} " , key); redisLimitTemplate.initRateLimiter(key, 40 - LIMIT_BUFFER, 1 , RateIntervalUnit.SECONDS); boolean acquire = redisLimitTemplate.tryAcquire(key, LIMITER_WAIT_TIME, TimeUnit.SECONDS); if (!acquire) { log.info("请求被限流控制,entId:{}" ,entId); throw new CustomException ("请求被限流控制,请稍后重试" ); } }
针对上述提到的最后一步消息推送,hcm-mobile服务会通过kafka发送一条消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 @Component @Slf4j public class HcmAbsenceMsgProducer { @Value("${topic.hcm_abs_batch_sync_channel_record}") private String topic; @Resource private InstanceProfileConfig instanceProfileConfig; @Resource private DefaultNoLogMsgProducer defaultNoLogMsgProducer; public void pushMsg (List<ChannelCheckInDataRes> resList, Long entId) { if (CollectionUtils.isEmpty(resList)) { return ; } String countAbs = MokaConfig.getInstance().getStrPropertyFromDefault(ApolloConstants.HCM_MOBILE_MOKA_ABSENCE_MSG_COUNT); int partitionRecord = resList.size(); if (StringUtils.isNotBlank(countAbs)) { partitionRecord = Integer.parseInt(countAbs); } Map<Long, List<ChannelCheckInDataRes>> employeeDataMap = resList.stream().collect(Collectors.groupingBy(ChannelCheckInDataRes::getEmployeeId)); for (Long employeeId : employeeDataMap.keySet()) { List<ChannelCheckInDataRes> employeeCheckInDataList = employeeDataMap.get(employeeId); List<List<ChannelCheckInDataRes>> checkInLists = ListUtils.partition(employeeCheckInDataList, partitionRecord); for (List<ChannelCheckInDataRes> singleEmployeeDataList : checkInLists) { AbsClockCheckInDataDto absClockCheckInDataDto = new AbsClockCheckInDataDto (); absClockCheckInDataDto.setEntId(entId); absClockCheckInDataDto.setBuId(singleEmployeeDataList.get(0 ).getBuId()); absClockCheckInDataDto.setEmployeeId(employeeId); absClockCheckInDataDto.setCheckInDataResDtoList(singleEmployeeDataList); Message message = Message.builder().sendTime(new Date ()) .msgId(employeeId) .isSequential(false ) .topic(getTopic(entId)) .body(JacksonUtils.toJson(absClockCheckInDataDto)) .build(); log.info("HcmAbsenceMsgProducer pushMsg -{}" , JacksonUtils.toJson(message)); defaultNoLogMsgProducer.pushMsg(message); } } } public String getTopic (Long entId) { String newTopic = topic; boolean shouldChange2GrayTopic = GrayUtils.shouldChange2GrayTopic(entId, instanceProfileConfig.getEnv(), instanceProfileConfig.getGrayReleased()); if (shouldChange2GrayTopic) { newTopic = "gray_" + topic; log.info("getTopic should be replace to new topic:{}, originTopic:{}" , newTopic, topic); } return newTopic; } }
其中 topic 字段将被赋予默认值 hcm_${spring.kafka.active}_abs_batch_sync_channel_record,${spring.kafka.active} 是一个占位符,它会在运行时被实际的配置值替换,例如 local、prod、staging
1 2 @Value("${topic.hcm_abs_batch_sync_channel_record}") private String topic;
至于该kafka消息的消费者,则看具体业务,
比如该打卡业务(hcm-absence-clock)中的同步飞书打卡数据,最终需要把指定租户下员工的飞书打卡记录写入到 **hcm_abs_lark_origin_clock_record**表中:
注意这里的containerFactory 创建了一个 Kafka 监听器容器工厂 ,这个工厂配置了 Kafka 消费者,使其能够支持批量消费
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Bean public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> batchConsumeListenContainerFactory () { log.info("---KafkaListenerContainerFactory---" ); ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory <>(); log.info("---ConcurrentKafkaListenerContainerFactory---new" ); factory.getContainerProperties().setAckMode(AbstractMessageListenerContainer.AckMode.MANUAL); factory.setConsumerFactory(this .consumerFactory()); log.info("---ConcurrentKafkaListenerContainerFactory---setConsumerFactory" ); factory.setConcurrency(this .concurrency); factory.getContainerProperties().setPollTimeout(2500L ); factory.getContainerProperties().setIdleEventInterval(6000L ); factory.setBatchListener(true ); log.info("---ConcurrentKafkaListenerContainerFactory---return--" ); return factory; }
在从 Kafka 消息中提取批量同步的打卡记录数据,按照员工的唯一键进行分组,构建一个映射关系,其中键是员工的唯一键,值是该员工对应的打卡记录列表后,就执行真正的batchSync批量同步逻辑 同步打卡数据按employeeId分组 :==batchSyncChannelRecordService.handleChannelRecords(employeeUniqkeyChannelRecordsMap);==
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public void handleChannelRecords (Map<String, List<ChannelCheckInDataResDto>> employeeUniqkeyChannelRecordsMap) { if (MapUtils.isEmpty(employeeUniqkeyChannelRecordsMap)) { return ; } MokaStopWatch stopWatch = new MokaStopWatch ("批量同步打卡数据" ); stopWatch.start("处理当前同步的数据以及状态" ); handleChannelSyncTaskData(employeeUniqkeyChannelRecordsMap); stopWatch.stop(); stopWatch.start("处理原始同步的打卡数据" ); Map<String, List<ClockInRecord>> employeeUniqKeyRecordsMap = Maps.newHashMap(); for (String employeeUniqKey : employeeUniqkeyChannelRecordsMap.keySet()) { List<ChannelCheckInDataResDto> channelRecords = employeeUniqkeyChannelRecordsMap.get(employeeUniqKey); Long employeeId = ClockRecordUtil.parseEmployeeIdFromEmployeeUniqKey(employeeUniqKey); if (CollectionUtils.isEmpty(channelRecords)) { log.info("{}没有需要同步的数据" , employeeId); continue ; } String key = SYNC_CHANNEL_DATA_KEY_PREFIX + employeeId; RLock lock = redissonClient.getLock(key); try { boolean lockFlag = lock.tryLock(10 , TimeUnit.SECONDS); if (!lockFlag) { log.error("当前员工正在同步打卡数据: {}" , employeeId); continue ; } Map<SyncTypeEnum, List<ChannelCheckInDataResDto>> channelRecordsMap = channelRecords.stream().collect(Collectors.groupingBy(ChannelCheckInDataResDto::getChannel)); Map<SyncTypeEnum, ChannelOriginRecordService> channelServiceMap = syncClockInRecordFactory.getSyncChannelRecordsByChannels(channelRecordsMap.keySet()); List<ClockInRecord> clockInRecords = Lists.newArrayList(); for (SyncTypeEnum channel : channelServiceMap.keySet()) { ChannelOriginRecordService originRecordService = channelServiceMap.get(channel); if (Objects.isNull(originRecordService)) { log.error("没有找到渠道对应的原始记录处理方式: {}, employeeUniqKey: {}" , channel, employeeUniqKey); continue ; } List<ClockInRecord> curChannelRecords = originRecordService.batchHandleOriginRecords(channelRecordsMap.getOrDefault(channel, Lists.newArrayList())); clockInRecords.addAll(curChannelRecords); } employeeUniqKeyRecordsMap.put(employeeUniqKey, clockInRecords); } catch (Exception e) { log.error("{}员工打卡数据同步失败" , employeeId, e); } finally { if (lock.isHeldByCurrentThread() && lock.isLocked()) { lock.unlock(); } } } stopWatch.stop(); stopWatch.start("保存数据" ); transactionTemplate.execute(new TransactionCallbackWithoutResult () { @Override protected void doInTransactionWithoutResult (TransactionStatus transactionStatus) { List<ClockInRecord> totalRecords = employeeUniqKeyRecordsMap.values().stream().flatMap(Collection::stream).collect(Collectors.toList()); batchSaveClockRecords(totalRecords); } }); stopWatch.stop(); stopWatch.start("推送消息" ); TransactionAsyncExecutor.asyncExecute(() -> postHandleResult(employeeUniqKeyRecordsMap)); stopWatch.stop(); log.info("数据同步耗时:{}" , stopWatch.prettyPrint()); }
注意这一行代码,它会获取通道对应的原始打卡记录列表,这里获取的就是飞书
1 List<ClockInRecord> curChannelRecords = originRecordService.batchHandleOriginRecords(channelRecordsMap.getOrDefault(channel, Lists.newArrayList()));
最后调用larkService下的batchSave方法,完成打卡记录的同步:
对应的mapper文件为:
1 2 3 4 5 6 7 8 9 <insert id ="batchInsert" keyColumn ="id" keyProperty ="id" parameterType ="map" useGeneratedKeys ="true" > insert into hcm_abs_lark_origin_clock_record (ent_id, bu_id, user_id, corp_id, employee_id, detail, lark_record_id, check_time, batch_number) values <foreach collection ="list" item ="item" separator ="," > (#{item.entId}, #{item.buId}, #{item.userId}, #{item.corpId}, #{item.employeeId}, #{item.detail}, #{item.larkRecordId}, #{item.checkTime}, #{item.batchNumber}) </foreach > </insert >
数据库中的记录为:
2、实时打卡—考勤机同步 目前pp支持了两类考勤机:天敏考勤机、中控考勤机。两类考勤机在接入流程和数据交互流程上不全相同
传输协议
人脸检测
人员下发
打卡数据获取
天敏考勤机
websocket(人员下发、心跳检测)+http(打卡数据上报)
已接入
考勤机逐个下发
主动上报
中控考勤机
http
暂未接入
中控server下发
主动定期拉取
架构图 天敏考勤机服务架构图 如下:
这里需要关注几个点:
考勤机的鉴权:websocket的握手阶段(协议未升级前的步骤)可以拿到请求中传入的param,通过这个param我们可以对考勤机进行鉴权 –给每个住户分配一个key, 请求进来时,对key进行有效判断
怎么识别某个考勤机是哪个租户的?考勤机连接成功后,websocket会理解给考勤机发送一个deviceInfo的消息,deviceInfo的应答内容中有考勤机的mac地址,后台通过mac地址,识别出来这个考勤机是哪个租户的 。后续session回话管理会将mac地址和socket链接建立关系
问题:
目前线上和灰度是各自两台websocket, 通过上面的架构图可以看出,websocket server和gateway是长连接的形式: 如果有一台websocket server出现问题,websocket进行连接重建,出问题的那台websocket启动成功后,正常情况下是没有连接的 。线上暂时未发现这个情况出现,因为考勤机中断后,重新建立连接时,可以选择到其他的机器
考勤机天敏是支持http协议的,但是我们选择了websocket协议,这里的原因和背景是什么? 如果使用http协议,考勤机需要提供一个可以被访问的外网地址,在使用场景下不太合适
流程图 天敏考勤机交互流程V1:
天敏考勤机交互流程V2:
3、实时打卡—Moka打卡 MokaPeople 移动端打卡属于实时打卡的一种,旧的流程图如下所示:
1.新的移动端实时打卡入口在ClockOnPageController内(==/v2/m/clockOn==):
2.构建打卡上下文、选择对应的打卡Processor(WIFI、GPS、OutSide)、进入打卡核心流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public ClockOnResultDto clockOn (ClockOnReqV2Dto clockOnReqDto, Long entId, Long buId, Long employeeId) { StopWatch stopWatch = new MokaStopWatch ("打卡接口" ); stopWatch.start("打卡上下文构建" ); ClockOnResultDto clockOnResultDto = new ClockOnResultDto (); Date attendanceDay = clockOnReqDto.getAttendanceDay(); Date clockInTime = DateTime.now().millisOfSecond().withMinimumValue().toDate(); ClockOnContext clockOnContext = ClockOnContext.builder().entId(entId).buId(buId).employeeId(employeeId) .attendanceDay(attendanceDay) .needCheckOfficeStaff(true ) .macAddress(clockOnReqDto.getMacAddress()) .longitude(clockOnReqDto.getLongitude()) .latitude(clockOnReqDto.getLatitude()) .gpsAddress(clockOnReqDto.getGpsAddress()) .deviceId(clockOnReqDto.getDeviceId()) .description(clockOnReqDto.getDescription()) .attachment(clockOnReqDto.getAttachment()) .relatedRecordId(clockOnReqDto.getRelatedRecordId()) .relatedRecordType(clockOnReqDto.getRelatedRecordType()) .clockTime(clockInTime) .sourceType(ClockRecordSourceTypeEnum.CLOCK.getValue()) .build(); List<AbstractClockTypeProcessor> processorList = Lists.newArrayList(wifiClockOn, gpsClockOn, outSideClockOn).stream().sorted(Comparator.comparing(AbstractClockTypeProcessor::sortOrder)).collect(toList()); AbstractClockTypeProcessor validProcessor = null ; stopWatch.stop(); stopWatch.start("打卡处理器执行" ); for (AbstractClockTypeProcessor processor : processorList) { if (!processor.ruleOpen(clockOnContext)) { continue ; } if (!processor.isValid(clockOnContext)) { continue ; } validProcessor = processor; break ; } stopWatch.stop(); stopWatch.start("打卡核心流程" ); if (validProcessor != null ) { addClockRecordAndPushSuccessNotify(clockOnContext, validProcessor); clockOnResultDto.setClockInTime(clockInTime); clockOnResultDto.setClockOnStatus(true ); } else { clockOnResultDto.setClockInTime(null ); clockOnResultDto.setClockOnStatus(false ); } stopWatch.stop(); log.info(stopWatch.prettyPrint()); return clockOnResultDto; }
3.(addClockRecordAndPushSuccessNotify(clockOnContext, validProcessor))添加打卡记录,并发送成功消息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public void addClockRecordAndPushSuccessNotify (ClockOnContext clockOnContext, AbstractClockTypeProcessor processor) { StopWatch stopWatch = new StopWatch ("移动端打卡" ); Long entId = clockOnContext.getEntId(); Long buId = clockOnContext.getBuId(); Long employeeId = clockOnContext.getEmployeeId(); Date attendanceDay = clockOnContext.getAttendanceDay(); stopWatch.start("记录打卡记录" ); processor.addClockRecord(clockOnContext); stopWatch.stop(); stopWatch.start("rpc触发打卡考勤核算" ); attendanceRecordV2Service.clockCalculate(entId, buId, employeeId, attendanceDay); stopWatch.stop(); stopWatch.start("发送打卡成功异步通知" ); ClockSuccessNotifyContext clockSuccessNotifyContext = ClockSuccessNotifyContext.buildClockRecordContextFromClockOnAction(clockOnContext); clockNoticeMsgPushService.asyncPushClockSuccessNotify(clockSuccessNotifyContext); stopWatch.stop(); log.info(stopWatch.prettyPrint()); }
这一步骤主要做了三件事:
打卡记录入库(事务保证Moka打卡表数据和打卡总表数据一致性)
录入 moka people 原始打卡记录表hcm_abs_moka_clock_record:
录入打卡记录总表 hcm_abs_clock_in_record:
RPC 触发打卡考勤核算(加入判断核算降级逻辑): 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public void clockCalculate (Long entId, Long buId, Long employeeId, Date attendanceDay) { DegradationModelEnum degradationModel = imitateClockFailedBackHandler.degradationModel(); try { if (degradationModel == DegradationModelEnum.ACTIVE){ log.info("打卡实时核算主动触发降级,entId:{},employeeId:{}" ,entId,employeeId); Period<Day> period = Period.between(Day.of(attendanceDay), Day.of(attendanceDay)); BatchCalculateMessageDto batchCalculateMessageDto = BatchCalculateMessageDto .buildBatchCalculateMessage(Tenant.of(entId, buId), period, Lists.newArrayList(employeeId)); clockInRecordAddMsgProducer.pushBatchCalculateMsg(batchCalculateMessageDto); }else { ClockCalculateDto clockCalculateDto = new ClockCalculateDto (); clockCalculateDto.setEntId(entId); clockCalculateDto.setBuId(buId); clockCalculateDto.setEmployeeId(employeeId); clockCalculateDto.setWorkflowStatusList(Lists.newArrayList(WorkflowStatusEnum.APPROVED)); clockCalculateDto.setCalculateDate(attendanceDay); clockCalculateDto.setUid(employeeId); clockCalculateDto.setSourceType(AttendanceCalculateSourceTypeEnum.CLOCK); ResultDto clockCalculateResult = attendanceCalculateClient.clockCalculate(clockCalculateDto); if (clockCalculateResult == null || !clockCalculateResult.success()) { log.info("clockCalculate failed, param:{}, result:{}" , JacksonUtils.toJson(clockCalculateDto), JacksonUtils.toJson(clockCalculateResult)); throw new CustomException ("打卡核算失败" ); } } } catch (Exception e) { log.warn("考勤核算失败 entId:{}, employeeId:{},attendanceDay:{}" , entId, employeeId, attendanceDay, e); if (degradationModel == DegradationModelEnum.PASSIVE){ log.error("调用实时考勤核算报错,被动降级模式,触发降级" ); Period<Day> period = Period.between(Day.of(attendanceDay).add(-1 ), Day.of(attendanceDay).add(1 )); BatchCalculateMessageDto batchCalculateMessageDto = BatchCalculateMessageDto.builder() .entId(entId) .buId(buId) .employeeIdList(Lists.newArrayList(employeeId)) .beginDate(period.getStart().toDate()) .endDate(period.getEnd().toDate()) .sourceType(AttendanceCalculateSourceTypeEnum.CLOCK_MOKA) .triggerOverTime(true ) .uid(1L ) .build(); clockInRecordAddMsgProducer.pushBatchCalculateMsg(batchCalculateMessageDto); } } }
判断降级后会发送kafka消息:
hcm-attendance 接收消息进行考勤批量核算:
Tips:降级模式下的核算与非降级模式下的核算逻辑区别在哪里🧐?
如果走降级:则发送一个kafka消息至指定topic,并不关注什么下游消费者时候消费
如果不走降级模式:则执行实时核算:
那么如何判断该走 降级/非降级 链路呢?
在下列degradationModel方法中,首先尝试从配置中心获取打卡降级模式的配置项值。它使用了MokaConfig.getInstance().getPropertyFromDefault方法,该方法会尝试从配置中心获取名为CLOCK_DEGRADATION_MODEL的配置项的值。如果获取失败,则默认为被动降级模式(DegradationModelEnum.PASSIVE)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 DegradationModelEnum degradationModel = imitateClockFailedBackHandler.degradationModel();public DegradationModelEnum degradationModel () { try { String degradationModel = MokaConfig.getInstance().getPropertyFromDefault(CLOCK_DEGRADATION_MODEL, String.class, DegradationModelEnum.PASSIVE.name()); return DegradationModelEnum.parse(degradationModel); }catch (Exception e){ log.error("查询打卡降级模式失败,默认关闭降级" ); return DegradationModelEnum.OFF; } }
apollo配置如下:
可以看出 Key 为CLOCK_DEGRADATION_MODEL对应的 Value 默认值为 Passive ——被动降级 ,因此只有在远程调用attendanceCalculateClient.clockCalculate()异常时,会捕捉异常catch代码块执行降级逻辑:
发送打卡成功异步通知 1 clockNoticeMsgPushService.asyncPushClockSuccessNotify(clockSuccessNotifyContext);
发送打卡成功通知时通过自定义线程池来发送:
推送消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 @Override public void asyncPushClockSuccessNotify (ClockSuccessNotifyContext clockSuccessNotifyContext) { CLOCK_SUCCESS_NOTICE_MSG_SEND_THREAD_POOL.execute(() -> { try { Long entId = clockSuccessNotifyContext.getEntId(); boolean isOff = ApolloUtil.isClockSuccessNotifySwitchIsOff(entId); if (isOff) { log.info("当前租户打卡成功提醒已关闭, entId:{}" , entId); return ; } log.info("打卡记录推送打卡成功提醒通知 record : {}" , clockSuccessNotifyContext.toString()); for (ClockSuccessNotifyCheck clockSuccessNotifyCheck : clockNotifyCheckList) { if (!clockSuccessNotifyCheck.verifyNeedNotify(clockSuccessNotifyContext)) { log.info("打卡成功提醒校验失败,不发送打卡通知" ); return ; } } log.info("员工打卡成功推送打卡成功消息 pushClockSuccessNotify entId :{}, bu:{}, uid:{}" , clockSuccessNotifyContext.getEntId(), clockSuccessNotifyContext.getBuId(), clockSuccessNotifyContext.getEmployeeId()); PushMsg pushMsg = new PushMsg (); pushMsg.setTitle(generateClockTitle(clockSuccessNotifyContext)); pushMsg.setMsg(generateClockMsg(clockSuccessNotifyContext)); pushMsg.setMsgType(PushMsg.TYPE_CLOCK_NOTICE); pushMsg.setMsgOrigId(0L ); pushMsg.setMsgTargIdList(Collections.singletonList(clockSuccessNotifyContext.getEmployeeId())); pushMsg.setMsgId(PushMsgKeyUtil.generateKeyWithSnowFlake()); pushMsg.setEntId(clockSuccessNotifyContext.getEntId().intValue()); pushMsg.setBuId(clockSuccessNotifyContext.getBuId().intValue()); pushMsg.setCreateTime(System.currentTimeMillis()); EmployeeAttendanceRuleDetailDto attendanceRuleDetailDto = clockSuccessNotifyContext.getAttendanceRuleDetailDto(); AttendanceRuleClockDto clockDto = attendanceRuleDetailDto.getClockInfo(); if (clockDto.getIsNeedClock() || clockDto.getIsAllowOutsideClock()) { pushMsg.setHaveRedirectUrl(true ); } else { pushMsg.setHaveRedirectUrl(false ); } Message message = Message.builder() .topic(topic) .body(JacksonUtils.toJson(pushMsg)) .build(); boolean pushFlag = defaultMsgProducer.pushMsg(message); if (pushFlag) { log.info("打卡成功消息推送kafka success pushClockSuccessNotify msg ={}" , JacksonUtils.toJson(message)); } else { log.warn("打卡成功消息推送kafka失败 pushClockSuccessNotify msg ={}" , JacksonUtils.toJson(message)); } } catch (Exception e) { log.error("打卡记录推送打卡成功提醒通知失败, record : {}" , JacksonUtils.toJson(clockSuccessNotifyContext), e); } }); }
打卡链路优化 背景与问题 目前打卡是假勤里面用的最多的一个业务,加班、考勤核算、出差、外出都可能会用打卡作为基础数据,所以打卡数据能及时同步、员工打卡动作能快速流畅的完成,对系统业务功能和用户体验非常重要。
但目前我们系统打卡还存在一定问题,主要是(划线的本次方案未解决):
1、员工打卡的时候由于attendance服务的压力,有可能模拟核算失败,员工打不了卡(移动端考勤核算速度慢)
2、同步打卡数据后发考勤核算消息是一条一条发的,增加了attendance服务的核算压力;校验是否已落库按单条记录加锁,效率低 (==同步打卡优化==)
3、同步打卡的数据源应用限流,导致我们打卡数据不能及时同步(==同步打卡优化==)
4、如果员工在第三方应用补卡,超过我们最大同步时间,同步不了打卡数据(同步,当前超过x分钟也同步不过来)
5、入职未绑定到第三方应用或离职员工打卡同步不过来(同步,受第三方应用限制)
6、openapi没有来源方式字段(需求)
7、员工打卡调用了太多次考勤规则,absence服务压力增大(==实时打卡优化==)
原来流程 1、同步打卡流程
2、实时打卡链路优化
优化方案 :star2: 1、同步打卡流程优化 解决同步单条处理,无法批量合并发送考勤核算问题
优化预期效果:
1)调用第三方接口的次数减少,降低限流概率
2)按员工id指定分区发送打卡数据,减少锁冲突,批量处理数据,提高处理效率
3)合并打卡触发考勤核算消息,增加考勤核算效率
4)同步打卡入口都用同一套逻辑,方便维护
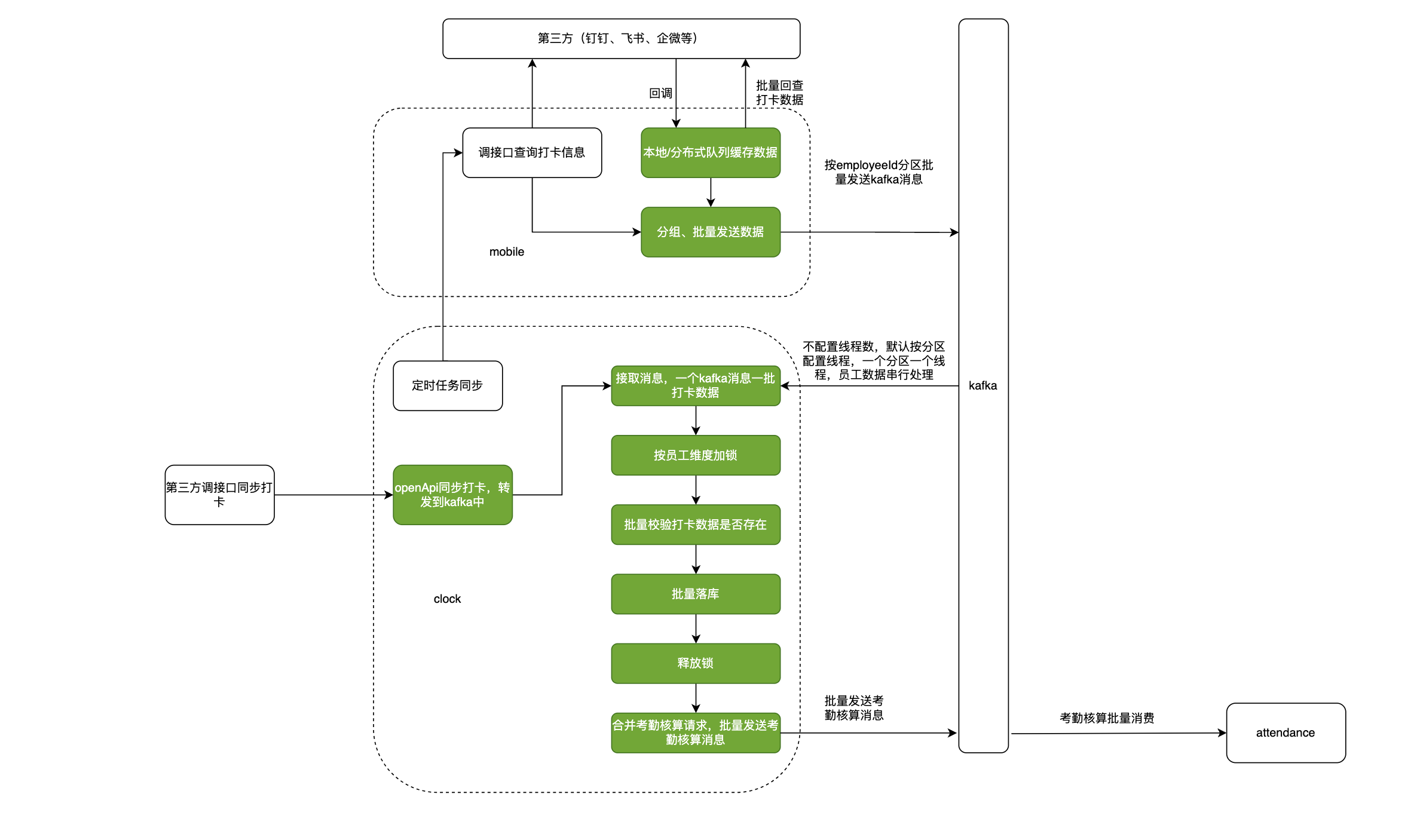
1.1 总览:
1.2 修改的功能点
功能点
所属服务
mobile 单机限流改成分布式,所有实例统一控制
mobile
同步打卡数据按employeeId分组,并按employeeId批量分发到指定分区,使用新的topic
mobile
回调结果增加缓存队列,10S或20条数据批量查询第三方打卡记录,并按employeeId批量分发到指定分区,使用新的topic
mobile
同步打卡处理流程处理,从新topic取打卡数据,按员工批量处理(加锁、落库等)
clock
发送考勤核算消息优化,同一个员工连续多天的打卡记录合并成一条考勤核算消息,多个员工的考勤核算消息批量发送,使用新的topic
clock
消费考勤核算消息修改,消费新的topic消息
attendance
每个功能点对应的代码块为:
限流优化 (1) 更改为分布式限流统一控制所有实例:
Before: 先来看看旧方案的处理方式(基于Guava的单机限流)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 private static final int DING_RATE_LIMIT_COUNT = 19 ;public void dingCheckinAcquireByCorpId (String corpId) { RateLimiter rateLimiter = null ; if (absDingCheckinLimiterMap.containsKey(corpId)) { rateLimiter = absDingCheckinLimiterMap.get(corpId); }else { rateLimiter = RateLimiter.create(DING_RATE_LIMIT_COUNT); absDingCheckinLimiterMap.put(corpId, rateLimiter); } rateLimiter.acquire(); } @CanIgnoreReturnValue public double acquire () { return this .acquire(1 ); } ---------------- public void dingCheckinAcquireByCorpId (String corpId) { RRateLimiter rRateLimiter = redissonClient.getRateLimiter("mobile:limiter:ding:checkin:" + corpId); rRateLimiter.trySetRate(RateType.OVERALL,40 ,1 , RateIntervalUnit.SECONDS); rRateLimiter.acquire(); } ----------------- public void dingCheckinAcquireByCorpId (String corpId) { String key = "mobile:limiter:ding:checkin:" + corpId; log.info("dingCheckinAcquireByCorpId:{} " , key); redisLimitTemplate.initRateLimiter(key, 40 - LIMIT_BUFFER, 1 , RateIntervalUnit.SECONDS); boolean acquire = redisLimitTemplate.tryAcquire(key, 3 , TimeUnit.SECONDS); if (!acquire) { throw new CustomException ("请求被限流控制,请稍后重试" ); } }
对应的RedisLimitTemplate类代码为:
Now: 更改为分布式限流
合并发送消息处理、加锁落库 (2) 将打卡数据按照员工id分组,批量分发、接收消息
(3) ==回调结果增加缓存队列==
对应的放到topic可以理解为缓存
调用它的地方就类似于本地缓存了,其实就是批量查询
(4)同步打卡处理流程处理,从新topic取打卡数据,按员工批量处理(加锁、落库 等):
路径为 BatchSyncChannelRecordServiceImpl#handleChannelRecords 方法:
(5)hcm-absence-attendance增加批量触发核算消息:
2、实时打卡链路优化 解决模拟核算失败,无法打卡,考勤规则调用频繁响应慢的问题
优化预期效果:打卡调用模拟核算接口次数减少、attendance服务挂了或者报错员工仍能正常打卡、查询考勤规则接口响应更快
2.1 总览:
服务降级
接口
描述
降级
/api/abs/clock/clockOnPage/v2/m/clockOn打卡的时候实时核算,异步通知
发送核算消息
/api/abs/clock/clockOnPage/v2/m/clockOutCheck打下班卡的时候先提前检查一下是否会签退异常,提示用户
不处理(当上面两个接口降级成无班次之后不会调用这个接口)
/api/abs/clock/clockOnPage/v2/m/queryClockRecord查询打卡记录,标记是签到或签退卡
同上
/api/abs/clock/clockOnPage/v2/m/queryRuleAndAttendanceInfo查询班次信息、打卡时间信息、考勤规则等
按无班次处理,clock内部按无班次模拟模算复制一份代码
/api/abs/clock/clockOnPage/v2/m/refreshGps刷新gps信息,会调考勤规则,触发自动打卡
不处理
/api/abs/clock/clockOnPage/v2/m/refreshWifi刷新wifi信息,会调考勤规则,触发自动打卡
不处理
2.3 接口合并:
queryRuleAndAttendanceInfo 和 queryClockRecord 接口合并成一个接口返回给前端
考勤规则接口缓存
由于在进行考勤核算时,需要查询员工对应考勤规则(hcm-absence下):
判断考勤规则数据是否命中、及是否需要加入缓存:
着重来看一下缓存相关逻辑
1、从缓存中查询规则信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 private List<EmployeeAttendanceRuleDetailDto> queryRuleFromCache (LocalDate start,LocalDate end,int attrType,List<Long> employeeIds,Long entId) { List<String> keys = new ArrayList <>(); List<LocalDate> dateList = this .getDates(start,end); dateList.forEach(date -> { employeeIds.forEach(employeeId -> { String key = getDetailCacheKey(entId,employeeId,date); keys.add(key); }); }); List<String> resStrs = redisTemplate.opsForValue().multiGet(keys); if (CollectionUtils.isEmpty(resStrs)){ return null ; } resStrs = resStrs.stream().filter(e -> Objects.nonNull(e)).collect(Collectors.toList()); if (resStrs.size()!=keys.size()){ return null ; } List<EmployeeAttendanceRuleDetailDto> ruleDtailList = new ArrayList <>(); for (String resStr:resStrs){ if (!NONE_RULE.equals(resStr)){ EmployeeAttendanceRuleDetailDto detailDto = JacksonUtils.fromJson(resStr,EmployeeAttendanceRuleDetailDto.class); ruleDtailList.add(dealRuleDetailDto(detailDto,attrType)); } } log.info("从缓存中查询考勤规则详情,employeeIds:{},start:{},end:{}" ,employeeIds,DateUtils.format(start.toDate(),DatePattern.YMD),DateUtils.format(end.toDate(),DatePattern.YMD)); return ruleDtailList; }
2、将员工加入到缓存队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 param.getEmployeeIds().forEach(employeeId -> { AddCacheMsg msg = AddCacheMsg.builder().employeeId(employeeId).entId(entId).buId(buId).build(); boolean res = redisListTool.sendMsgToList(CacheConstants.getAddCacheQueueName(),JacksonUtils.toJson(msg),String.valueOf(employeeId)); if (!res){ log.warn("员工加缓存失败:{}" ,employeeId); } }); public boolean sendMsgToList (String name, String msg, String key) { if (!StringUtils.isEmpty(name) && !StringUtils.isEmpty(key) && !StringUtils.isEmpty(msg)) { Boolean existed = this .redisTemplate.opsForSet().isMember("hcm:absence:queue:" + name + "_unique" , key); if (existed != null && existed) { log.warn("消息已在Redis中存在,不发送" ); CountStatisticUtil.increment("msgExisted" ); return false ; } else { Long res = this .redisTemplate.opsForList().leftPush("hcm:absence:queue:" + name, JSONObject.toJSONString(new RedisQueueMsg (key, msg))); if (res != null && res > 0L ) { this .redisTemplate.opsForSet().add("hcm:absence:queue:" + name + "_unique" , new String []{key}); this .redisTemplate.convertAndSend(this .config.getNoticeChannel(), name); CountStatisticUtil.increment("sendSuccess" ); return true ; } else { return false ; } } } else { CountStatisticUtil.increment("emptyMsg" ); return false ; } }
考勤规则降级设计 一、降级方案图示
降级的打卡记同步到正常打卡记录表生命周期:入库 → 验证有效状态 → 同步
改动点说明:
二、验证流程
验证流程只做验证,不做同步
三、同步流程
3、打卡分表 方案一: 按租户分表
配置里配置哪些租户需要单独分表,剩下租户使用原表;
当配置了租户分表后调用接口初始化租户的打卡表,然后迁移租户数据到目的表中;
打卡的crud通过mybatis插件修改表名,指向目标表;
优势:
1、可以根据租户打卡数据量来确定是否需要分到单独的表,或者把几个租户合到一个表里面,防止有的表数据多,有的表数据少,也可以把重点租户单独拉出来
2、同一个租户的数据在一个表中,对于业务查询或落库无任何影响,业务契合度很高,基本上不需要上层改动什么代码。
方案二: 按时间分表
2个月一张表,一张表数据量控制在500W以下,定时任务创建未来的表,分库分表框加处理数据库请求
优势:不需要人为干预分表,每个表的数据也比较均衡,但如果跨表查询可能比较麻烦点
打卡故障复盘 事故来龙去脉 影响范围:
业务影响:
受影响的业务场景 & 严重程度: 天九共享、浙江医学科技开发有限公司、迈格森等部分员工打不了卡
量化影响:
影响的客户数量: 3家客户提报
影响的数据量:
影响时间:2023-03-10 17:36~2023-03-10 17:41(从出错的日志看)
页面显示:
1、打卡页面提示错误,无法打卡
2、进不去打卡页面
影响租户:
租户
天九共享
浙江医学科技开发有限公司
成都迈格森教育咨询有限公司
广州小迈网络科技有限公司
北京希瑞亚斯科技有限公司
欢聚时代测试公司
北京蜜莱坞网络科技有限公司
事故发现渠道 :
2023-03-10 17:33 发现sentry频繁报错 ,17:39群里面反馈有员工打不了卡
事故时间线(尽量详尽) :
时间
操作 or 描述
2023-03-10 17:33
线上sentry问题群频繁报错,研发开始介入排查
2023-03-10 17:34
发现attendance有很多模拟模算报错,包括人事接口报错
2023-03-10 17:36
clock调模拟核算接口熔断
2023-03-10 17:39
服务侧同学在群里反馈用户打不了卡,人事同学删除redis缓存
2023-03-10 17:40
有同学反馈corebase接口有问题已回滚
2023-03-10 17:41
重新刷新缓存,打卡恢复正常
2023-03-10 18:10
clock和attendance增加一个pod
事故修复 研发视角 直接原因:
1、attendance 服务短时间有多个模拟核算的请求超过30s,clock配置的熔断策略是超时时间30s,窗口最小请求数量20,失败阈值是50%,超时直接熔断了
间接因素: 1、天九(751)在当天有很多组织调整,触发了考勤规则缓存刷新
部门变更触发刷新缓存规则的时候会刷整个租户的缓存,需要调人事接口查所有部门所有人员,接口报错,导致刷新缓存失败:
刷新缓存失败有个逻辑,会删除租户缓存标识,查询的时候如果发现没有这个标识,会直接从db中查询,整个接口性能就会下降
天九所有打卡员工在17:37后都直接走db查询,平均响应时间超过3s钟,当前请求量很大,影响上游attendance业务
17:39的时候重新刷新缓存查询正常,缓存刷新成功,打卡恢复
2、attendance服务下 模拟核算接口(/clockImitateCalculate)调用量突增,单个请求查基础数据并发线程40,一个请求同时需要提交6个任务,实际预期并发7个请求左右,当天天九很多员工打卡,他们前一天工作日日期、考勤规则、异常规则查询三个absence接口串行查询,整个基础数据耗时在6~7秒左右,不能及时响应打卡调用模拟核算接口的请求,请求都堆在线程中,后续请求超时导致clock熔断
3、core-base接口返回失败的原因 :grey_question:
天九更新部门数据会刷新缓存,先删除缓存再更新缓存,在并发更新缓存时查询缓存可能有数据缺失,导致本次缓存更新失败(本地缓存10S有效期)进而导致人事接口查询错误。
测试视角 打卡链路 如下:
打卡信息设置